
Fluid 是云原生分布式数据集编排和加速引擎,主要服务于云原生场景下的数据密集型应用,例如大数据应用、AI 应用等。本文将从数据编排和数据加速两个方面,介绍 Fluid 的主要工作原理。
架构
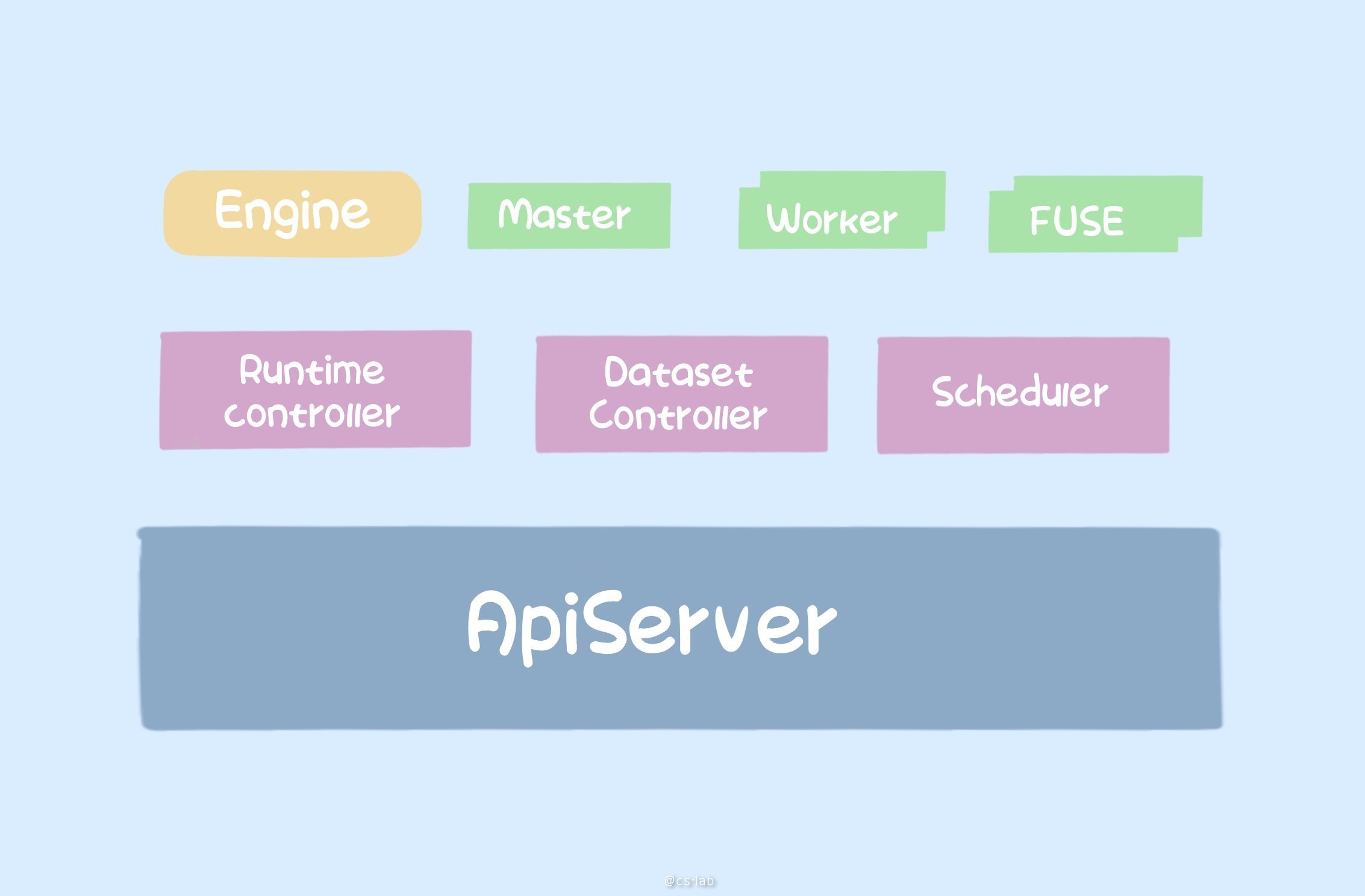
Fluid 的整个架构主要分为两个部分。
一是 Controller,包括 RuntimeController 及 DatasetController,分别管理 Runtime 和 Dataset 的生命周期,二者共同作用,以 helm chart 为基础,快速搭建出一套完整的分布式缓存系统,通常是 master + worker + fuse 的形式,向上提供服务。
master 是缓存系统的核心组件,通常是一个 pod;
worker 是组成缓存集群的组件,可以是多个 pod,可以设置个数;
fuse 是提供 POSIX 接口服务的组件;
二是调度器,在有缓存的情况下,调度器会根据 worker 的节点信息,使得上层应用 pod 尽可能调度到有缓存的节点。
数据编排
Fluid 有两个最主要的概念:Runtime 和 Dataset。
Runtime 指的是提供分布式缓存的系统,目前 Fluid 支持的 Runtime 类型有 JuiceFS、Alluxio、JindoFS,其中 Alluxio、JindoFS 都是典型的分布式缓存引擎;JuiceFS 是一款分布式文件系统,具备分布式缓存能力。本文会以 JuiceFS 为例,介绍 Fluid 的核心功能。
Dataset 是指数据集,是逻辑上相关的一组数据的集合,会被运算引擎使用,比如大数据的 Spark,AI 场景的 TensorFlow。对应到 JuiceFS 中,Dataset 也可以理解为一个 JuiceFS 的 Volume。
整个过程如下,Dataset Controller 监听 Dataset,Runtime Controller 监听对应的 Runtime,当二者一致时,RuntimeController 会启动 Engine,Engine 创建出对应的 Chart,里面包含 Master、Worker、FUSE 组件。同时,Runtime Controller 会定期同步数据(如总数据量、当前使用数据量等)状态更新 Dataset 和 Runtime 的状态信息。
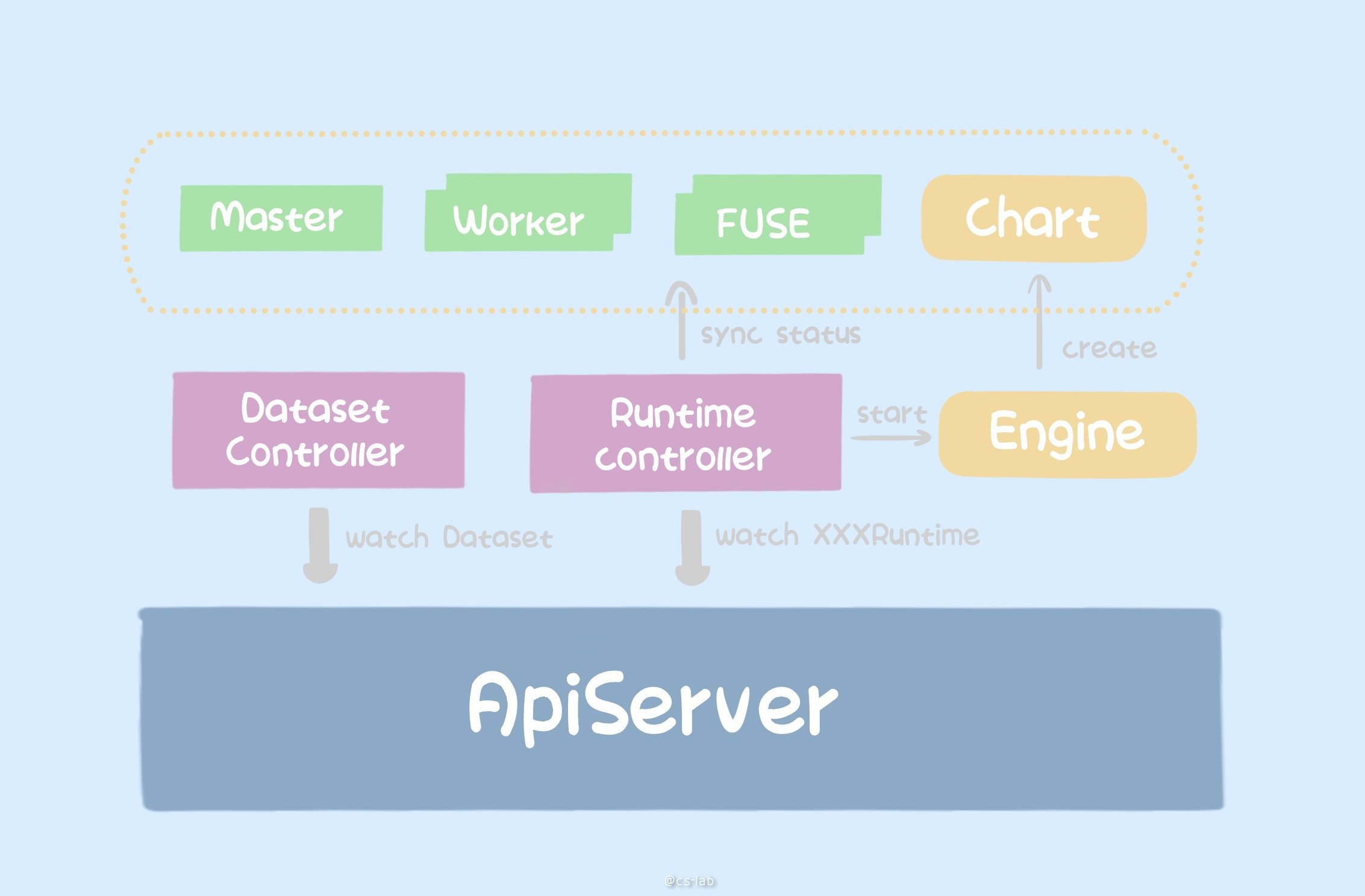
下面以 JuiceFS 为例,搭建一套 Fluid 环境,搭建好后组件如下:
$ kubectl -n fluid-system get po
NAME READY STATUS RESTARTS AGE
csi-nodeplugin-fluid-fczdj 2/2 Running 0 116s
csi-nodeplugin-fluid-g6gm8 2/2 Running 0 117s
csi-nodeplugin-fluid-twr4m 2/2 Running 0 116s
dataset-controller-5bc4bcb77d-844rz 1/1 Running 0 116s
fluid-webhook-7b4f48f647-s8c9w 1/1 Running 0 116s
juicefsruntime-controller-5d95878575-hj785 1/1 Running 0 116s
各个组件的作用:
dataset-controller:管理 Dataset 的生命周期
juicefsruntime-controller:管理 JuiceFSRuntime 生命周期,并快速搭建 JuiceFS 环境;
fluid-webhook:实现 Fluid 应用的缓存调度工作;
csi-nodeplugin:实现各引擎的挂载路径与应用之间的连接工作;
然后创建 Runtime 和 Dataset。具体操作可以参考官方文档:https://github.com/fluid-cloudnative/fluid/blob/master/docs/zh/samples/juicefs_runtime.md
$ kubectl get po
NAME READY STATUS RESTARTS AGE
jfsdemo-worker-0 1/1 Running 0 58m
jfsdemo-worker-1 1/1 Running 0 58m
JuiceFSRuntime 和 Dataset 创建好后,Runtime Controller 会根据其提供的参数创建 JuiceFS 的环境。JuiceFS 相对其他 Runtime 的特殊之处在于其没有 master 组件(因为其分布式缓存实现方式的特殊性),所以这里只看到启动了 worker 组件,构成了一个独立缓存集群(目前只有云服务版支持)。
Runtime Controller 启动 JuiceFS 的环境的方法是启动一个 helm chart,其渲染的 values.yaml 以 ConfigMap 的形式保存在集群中。查看 chart 如下:
$ helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
fluid default 1 2022-05-06 22:44:51.999227 +0800 +0800 deployed fluid-0.8.0 0.8.0-6a5acd3
jfsdemo-ee default 1 2022-05-12 19:18:00.069524643 +0800 +0800 deployed juicefs-0.2.0 v0.17.2
这里需要注意的是,从 v0.7.0 版本开始,Fluid 采用了 FUSE 客户端懒启动的方式,在有应用工作的时候,才启动 FUSE pod,以免造成不必要的资源浪费。
启动一个使用 Fluid Dataset 的应用:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
demo-app 1/1 Running 0 25s
jfsdemo-fuse-pd9zq 1/1 Running 0 25s
jfsdemo-worker-0 1/1 Running 0 60m
jfsdemo-worker-1 1/1 Running 0 60m
可以看到,应用启动后,FUSE 组件也启动成功。
数据加速
Fluid 另一个重要的功能是数据预加速。为了保证应用在访问数据时的性能,可以通过数据预加载提前将远程存储系统中的数据拉取到靠近计算结点的分布式缓存引擎中,使得消费该数据集的应用能够在首次运行时即可享受到缓存带来的加速效果。
在 Fluid 中,数据加速对应的是 DataLoad,也是一个 CRD,DatasetController 负责监听该资源,根据对应的 DataSet 启动 Job,执行数据预热操作。同时 Runtime Controller 向 Worker 同步缓存的数据信息,并更新 Dataset 的状态。
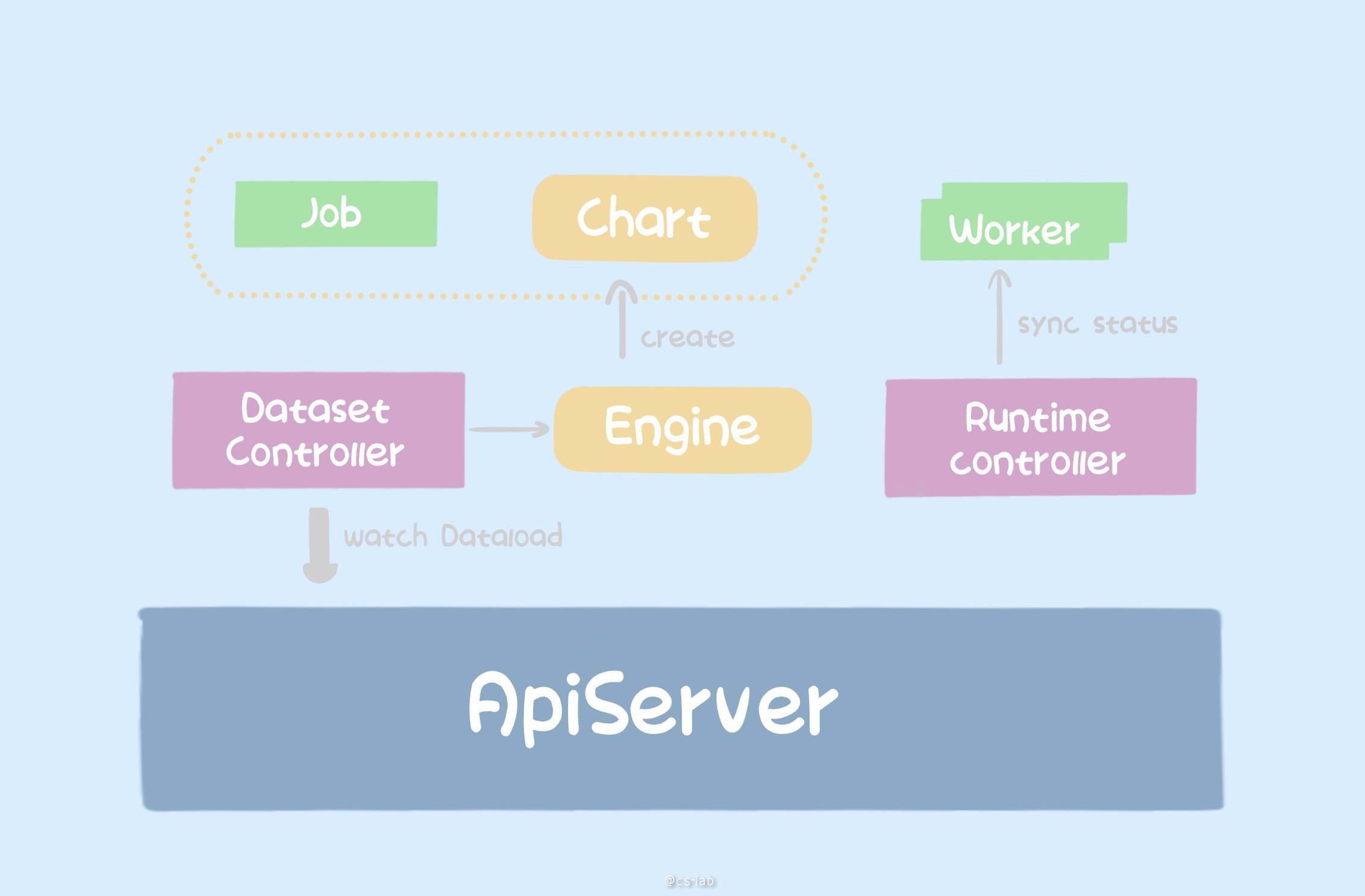
仍然以 JuiceFS DataLoad 为例:
apiVersion: data.fluid.io/v1alpha1
kind: DataLoad
metadata:
name: jfs-load
spec:
dataset:
name: jfsdemo
namespace: default
target:
- path: /dir1
- path: /dir2
比如原本文件系统中有两个子目录 /dir1 和 /dir2,target 中指定表示两个目录的数据都预热到缓存集群中。预热启动后:
$ kubectl get po
NAME READY STATUS RESTARTS AGE
jfs-load-ee-loader-job-mdjp2 0/1 Completed 0 15s
jfsdemo-ee-worker-0 1/1 Running 0 103m
jfsdemo-ee-worker-1 1/1 Running 0 103m
DatesetController 启动 dataload job 的方式也是启动一个 chart,其中包括一个 job 和 configMap:
$ helm list
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
fluid default 1 2022-05-06 22:44:51.999227 +0800 +0800 deployed fluid-0.8.0 0.8.0-6a5acd3
jfs-load-ee-loader default 1 2022-05-12 21:00:57.738708755 +0800 +0800 deployed fluid-dataloader-0.1.0 0.1.0
jfsdemo-ee default 1 2022-05-12 19:18:00.069524643 +0800 +0800 deployed juicefs-0.2.0 v0.17.2
当名为 loader-job 的 pod 状态为 Completed 时,表示预热过程已经完成。此时 DataLoad 的状态也变成了 Complete:
$ kubectl get dataload
NAME DATASET PHASE AGE DURATION
jfs-load-ee jfsdemo-ee Complete 34s 18s
而 Dataset 的 CACHED 和 CACHED PERCENTAGE 数值也会更新。CACHED 表示已缓存的数量,CACHED PERCENTAGE 表示缓存数据的比例,即 CACHED/UFS TOTAL SIZE。
$ kubectl get dataset
NAME UFS TOTAL SIZE CACHED CACHE CAPACITY CACHED PERCENTAGE PHASE AGE
jfsdemo-ee 7.00GiB 4.70GiB 80.00GiB 67.2% Bound 84m
总结
本文以 JuiceFS Runtime 为例,介绍了 Fluid 的两大核心功能,数据编排和数据加速。Fluid 适配了多种分布式缓存引擎,以统一的数据编排方式为上层数据密集型应用提供服务,使其不再拘泥于底层缓存引擎的部署和诸多参数细节,能够专注于自身的数据计算。


