
本文基于对 Kubernetes v1.19.0-rc.3 的源码阅读
Kubelet 作为 Kubernetes 的四大组件之一,维护了 pod 的整个生命周期,并且是 Kubernetes 创建 pod 的最后一环。本篇文章就来介绍一下 Kubelet 如何创建 pod。
Kubelet 的架构
首先看一个 Kubelet 的组件架构图,如下所示:
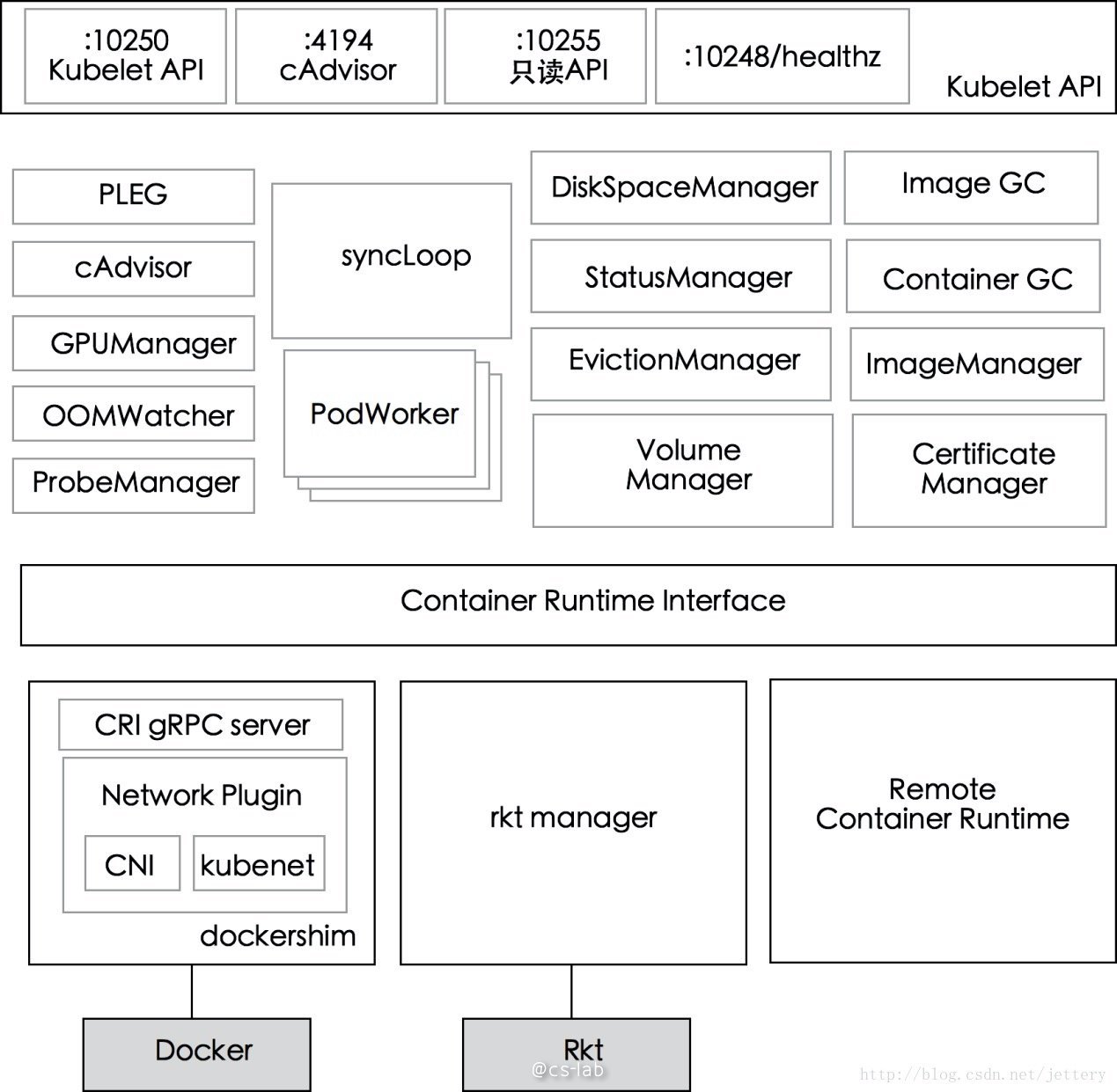
可以看到 Kubelet 主要分成三层:API 层、syncLoop 层、CRI 及以下。API 层很好理解,就是给外部提供接口的部分;syncLoop 层就是 Kubelet 的核心工作层,Kubelet 的主要工作都是围绕这个 syncLoop 展开,即控制循环,由生产者和消费者通过事件驱动循环运行;CRI 提供了容器和镜像的服务的接口,容器运行时可以以 CRI 插件的形式接入。
我们主要来看下 syncLoop 层的几个重要组件:
-
PLEG:调用容器运行时的接口来获取本节点 containers/sandboxes 的信息,与本地维护的 pod cache 进行对比,生成对应的 PodLifecycleEvent,然后通过 eventChannel 发送到 Kubelet syncLoop,然后由定时任务来同步 pod,最终达到用户的期望状态。
-
CAdvisor:集成在 Kubelet 中的容器监控工具,用于收集本节点和容器的监控信息。
-
PodWorkers:注册了多个 pod handler,分别处理 pod 的不同时间,包括创建、更新、删除等。
-
oomWatcher:系统 OOM 的监听器,会与 CAdvisor 模块之间建立 SystemOOM,通过 Watch 方式从 CAdvisor 那里收到的 OOM 信号,并产生相关事件。
-
containerGC:负责清理节点上的无用 container,具体的垃圾回收操作由容器运行时来实现。
-
imageGC:负责 node 节点的镜像回收,当本地的存放镜像的本地磁盘空间达到某阈值的时候,会触发镜像的回收,删除掉不被 pod 所使用的镜像。
-
Managers:包含各种 manager,管理与 pod 相关的各类资源。如 imageManager、volumeManager、evictionManager、statusManager、probeManager、runtimeManager、podManager。各 manager 各司其职,在 SyncLoop 中协同工作。
Kubelet 工作原理
如上面所说,Kubelet 的工作主要是围绕一个 SyncLoop 来展开,借助 go channel,各组件监听 loop 消费事件,或者往里面生产 pod 相关的事件,整个控制循环由事件驱动运行。可以用下图来表示:
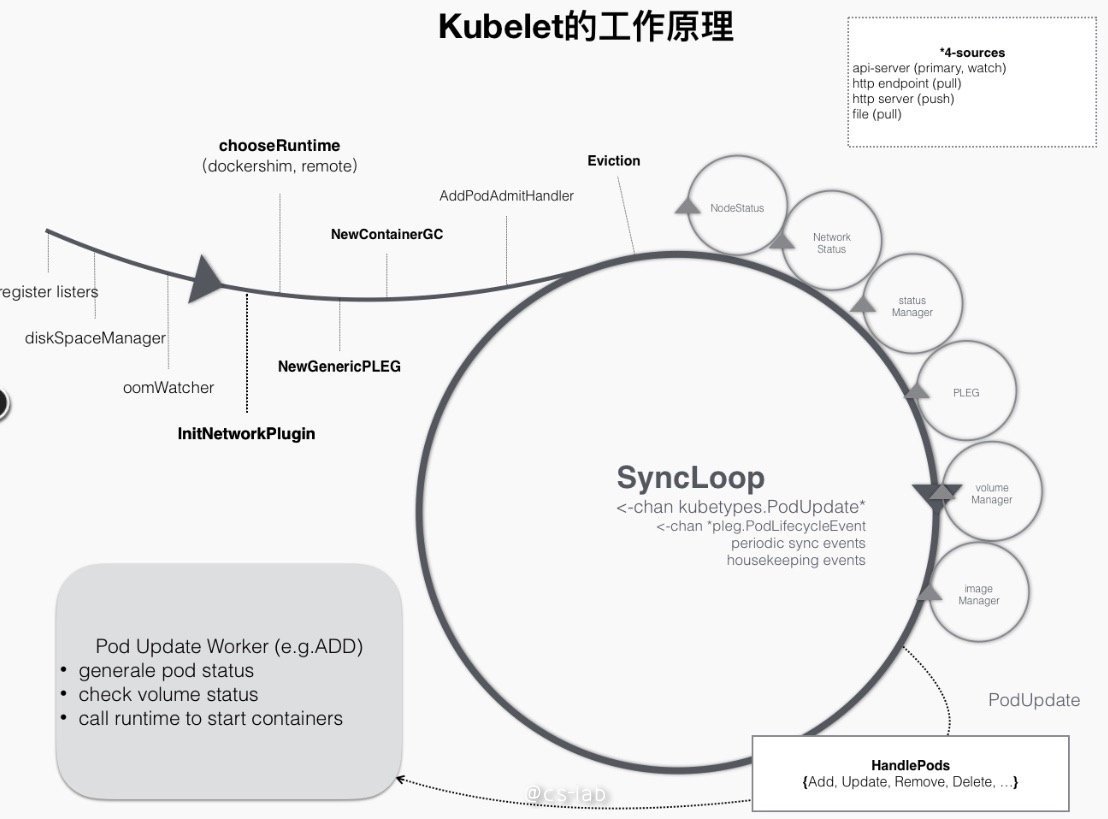
比如新建 pod 过程中,当一个 pod 被调度到某个 node 之后,就会触发 Kubelet 在循环控制里注册的 handler,如上图中的 HandlePods 部分。此时,Kubelet 检查 pod 在 Kubelet 内存中的状态,判断这是需要创建的 pod,从而触发 Handler 里的 ADD 事件对应的逻辑处理。
SyncLoop
我们来看下这个主循环 SyncLoop:
func (kl *kubelet) syncLoop(updates <-chan kubetypes.PodUpdate, handler SyncHandler) {
klog.Info("Starting kubelet main sync loop.")
// The syncTicker wakes up Kubelet to checks if there are any pod workers
// that need to be sync'd. A one-second period is sufficient because the
// sync interval is defaulted to 10s.
syncTicker := time.NewTicker(time.Second)
defer syncTicker.Stop()
housekeepingTicker := time.NewTicker(housekeepingPeriod)
defer housekeepingTicker.Stop()
plegCh := kl.pleg.Watch()
const (
base = 100 * time.Millisecond
max = 5 * time.Second
factor = 2
)
duration := base
// Responsible for checking limits in resolv.conf
// The limits do not have anything to do with individual pods
// Since this is called in syncLoop, we don't need to call it anywhere else
if kl.dnsConfigurer != nil && kl.dnsConfigurer.ResolverConfig != "" {
kl.dnsConfigurer.CheckLimitsForResolvConf()
}
for {
if err := kl.runtimeState.runtimeErrors(); err != nil {
klog.Errorf("skipping pod synchronization - %v", err)
// exponential backoff
time.Sleep(duration)
duration = time.Duration(math.Min(float64(max), factor*float64(duration)))
continue
}
// reset backoff if we have a success
duration = base
kl.syncLoopMonitor.Store(kl.clock.Now())
if !kl.syncLoopIteration(updates, handler, syncTicker.C, housekeepingTicker.C, plegCh) {
break
}
kl.syncLoopMonitor.Store(kl.clock.Now())
}
}
SyncLoop 起了一个死循环,循环里只调用了 syncLoopIteration 方法。而 syncLoopIteration 会对传入的所有 channel 遍历,发现任何一个管道有消息就交给 handler 去处理。
这些 channel 包括:
- configCh:该 channel 的生产者为 kubeDeps 对象中的 PodConfig 子模块提供,该模块将同时监听来自 file,http,apiserver 的 pod 信息的变化,一旦某个来源的 pod 信息发生了更新,就会向这个 channel 生产相关事件。
- plegCh:该 channel 的生产者为 pleg 子模块,该模块会周期性地向容器运行时查询当前所有容器的状态,如果状态发生变化,则向这个 channel 生产事件。
- syncCh:定时同步最新保存的 pod 状态。
- livenessManager.Updates():健康检查发现某个 pod 不可用,Kubelet 将根据 Pod 的 restartPolicy 自动执行正确的操作。
- houseKeepingCh:housekeeping 事件的管道,做 pod 清理工作。
syncLoopIteration 的代码:
func (kl *kubelet) syncLoopIteration(configCh <-chan kubetypes.PodUpdate, handler SyncHandler,
syncCh <-chan time.Time, housekeepingCh <-chan time.Time, plegCh <-chan *pleg.PodLifecycleEvent) bool {
select {
case u, open := <-configCh:
// Update from a config source; dispatch it to the right handler
// callback.
if !open {
klog.Errorf("Update channel is closed. Exiting the sync loop.")
return false
}
switch u.Op {
case kubetypes.ADD:
klog.V(2).Infof("SyncLoop (ADD, %q): %q", u.Source, format.Pods(u.Pods))
// After restarting, Kubelet will get all existing pods through
// ADD as if they are new pods. These pods will then go through the
// admission process and *may* be rejected. This can be resolved
// once we have checkpointing.
handler.HandlePodAdditions(u.Pods)
case kubetypes.UPDATE:
klog.V(2).Infof("SyncLoop (UPDATE, %q): %q", u.Source, format.PodsWithDeletionTimestamps(u.Pods))
handler.HandlePodUpdates(u.Pods)
case kubetypes.REMOVE:
klog.V(2).Infof("SyncLoop (REMOVE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodRemoves(u.Pods)
case kubetypes.RECONCILE:
klog.V(4).Infof("SyncLoop (RECONCILE, %q): %q", u.Source, format.Pods(u.Pods))
handler.HandlePodReconcile(u.Pods)
case kubetypes.DELETE:
klog.V(2).Infof("SyncLoop (DELETE, %q): %q", u.Source, format.Pods(u.Pods))
// DELETE is treated as a UPDATE because of graceful deletion.
handler.HandlePodUpdates(u.Pods)
case kubetypes.SET:
// TODO: Do we want to support this?
klog.Errorf("Kubelet does not support snapshot update")
default:
klog.Errorf("Invalid event type received: %d.", u.Op)
}
kl.sourcesReady.AddSource(u.Source)
case e := <-plegCh:
if e.Type == pleg.ContainerStarted {
// record the most recent time we observed a container start for this pod.
// this lets us selectively invalidate the runtimeCache when processing a delete for this pod
// to make sure we don't miss handling graceful termination for containers we reported as having started.
kl.lastContainerStartedTime.Add(e.ID, time.Now())
}
if isSyncPodWorthy(e) {
// PLEG event for a pod; sync it.
if pod, ok := kl.podManager.GetPodByUID(e.ID); ok {
klog.V(2).Infof("SyncLoop (PLEG): %q, event: %#v", format.Pod(pod), e)
handler.HandlePodSyncs([]*v1.Pod{pod})
} else {
// If the pod no longer exists, ignore the event.
klog.V(4).Infof("SyncLoop (PLEG): ignore irrelevant event: %#v", e)
}
}
if e.Type == pleg.ContainerDied {
if containerID, ok := e.Data.(string); ok {
kl.cleanUpContainersInPod(e.ID, containerID)
}
}
case <-syncCh:
// Sync pods waiting for sync
podsToSync := kl.getPodsToSync()
if len(podsToSync) == 0 {
break
}
klog.V(4).Infof("SyncLoop (SYNC): %d pods; %s", len(podsToSync), format.Pods(podsToSync))
handler.HandlePodSyncs(podsToSync)
case update := <-kl.livenessManager.Updates():
if update.Result == proberesults.Failure {
// The liveness manager detected a failure; sync the pod.
// We should not use the pod from livenessManager, because it is never updated after
// initialization.
pod, ok := kl.podManager.GetPodByUID(update.PodUID)
if !ok {
// If the pod no longer exists, ignore the update.
klog.V(4).Infof("SyncLoop (container unhealthy): ignore irrelevant update: %#v", update)
break
}
klog.V(1).Infof("SyncLoop (container unhealthy): %q", format.Pod(pod))
handler.HandlePodSyncs([]*v1.Pod{pod})
}
case <-housekeepingCh:
if !kl.sourcesReady.AllReady() {
// If the sources aren't ready or volume manager has not yet synced the states,
// skip housekeeping, as we may accidentally delete pods from unready sources.
klog.V(4).Infof("SyncLoop (housekeeping, skipped): sources aren't ready yet.")
} else {
klog.V(4).Infof("SyncLoop (housekeeping)")
if err := handler.HandlePodCleanups(); err != nil {
klog.Errorf("Failed cleaning pods: %v", err)
}
}
}
return true
}
创建 pod 的过程
Kubelet 创建 pod 的过程是由 configCh 中的 ADD 事件触发的,那么下面主要看下 Kubelet 接收到 ADD 事件后的主要流程。
Handler
当 configCh 中出现了 ADD 事件,loop 会触发 SyncHandler 的 HandlePodAdditions 方法。这个方法的流程可以用下面这张流程图描述:

首先 handler 会将所有的 pod 安装创建时间进行排序,然后逐个进行处理。
首先将 pod 添加到 podManager 中,以方便后续操作;然后判断其是否为 mirror pod,如果是将作为 mirror pod 处理,否则按照正常 pod 处理,这里解释一下 mirror pod:
mirror pod 是 static pod 在 kueblet 在 apiserver 创建的一份副本。由于 static pod 是由 Kubelet 直接管理的,apiserver 并不会感知到 static pod 的存在,其生命周期都由 Kubelet 直接托管。为了可以通过 kubectl 命令查看对应的 pod,并且可以通过 kubectl logs 命令直接查看到static pod 的日志信息,Kubelet 通过 apiserver 为每一个 static pod 创建一个对应的 mirror pod。
接着判断 pod 是否能再该节点上运行,也就是所谓的 Kubelet 中的 pod 准入控制,准入控制主要包括这几方面:
- 节点是否满足 pod 的亲和性规则
- 节点是否有足够的资源分配给 pod
- 节点是否使用 HostNetwork 或者 HostIPC,若使用了,是否在节点的白名单里
- /proc 挂载目录满足要求
- pod 是否配置且是否配置正确的 AppArmor
当所有的条件都满足后,最后触发 podWorker 同步 pod。
HandlePodAdditions 对应的代码如下:
func (kl *kubelet) HandlePodAdditions(pods []*v1.Pod) {
start := kl.clock.Now()
sort.Sort(sliceutils.PodsByCreationTime(pods))
for _, pod := range pods {
existingPods := kl.podManager.GetPods()
// Always add the pod to the pod manager. Kubelet relies on the pod
// manager as the source of truth for the desired state. If a pod does
// not exist in the pod manager, it means that it has been deleted in
// the apiserver and no action (other than cleanup) is required.
kl.podManager.AddPod(pod)
if kubetypes.IsMirrorPod(pod) {
kl.handleMirrorPod(pod, start)
continue
}
if !kl.podIsTerminated(pod) {
// Only go through the admission process if the pod is not
// terminated.
// We failed pods that we rejected, so activePods include all admitted
// pods that are alive.
activePods := kl.filterOutTerminatedPods(existingPods)
// Check if we can admit the pod; if not, reject it.
if ok, reason, message := kl.canAdmitPod(activePods, pod); !ok {
kl.rejectPod(pod, reason, message)
continue
}
}
mirrorPod, _ := kl.podManager.GetMirrorPodByPod(pod)
kl.dispatchWork(pod, kubetypes.SyncPodCreate, mirrorPod, start)
kl.probeManager.AddPod(pod)
}
}
podWorkers 的工作
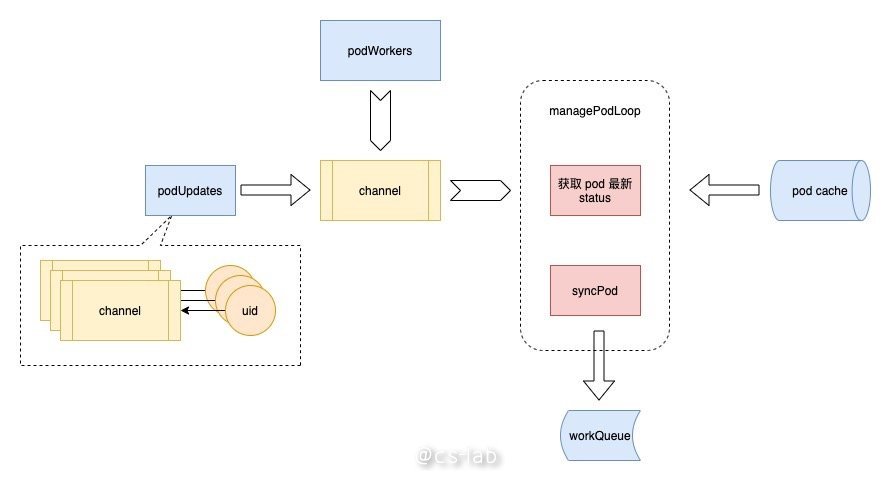
接下来看看 podWorker 的工作。podWorker 维护了一个 map 叫 podUpdates,以 pod uid 为 key,为每个 pod 维护一个 channel;当 pod 有事件过来的时候,首先从这个 map 里获取对应的 channel,然后启动一个 goroutine 监听这个 channel,并执行 managePodLoop;另一方面 podWorker 向这个 channel 中传入需要同步的 pod。
managePodLoop 接收到事件后,会先从 pod cache 中获取该 pod 最新的 status,以确保当前处理的 pod 是最新状态;然后调用 syncPod 方法,将其同步后的结果记录在 workQueue 中,等待下一次定时同步任务处理。
整个过程如下图所示:
podWorker 中处理 pod 事件的代码:
func (p *podWorkers) UpdatePod(options *UpdatePodOptions) {
pod := options.Pod
uid := pod.UID
var podUpdates chan UpdatePodOptions
var exists bool
p.podLock.Lock()
defer p.podLock.Unlock()
if podUpdates, exists = p.podUpdates[uid]; !exists {
podUpdates = make(chan UpdatePodOptions, 1)
p.podUpdates[uid] = podUpdates
go func() {
defer runtime.HandleCrash()
p.managePodLoop(podUpdates)
}()
}
if !p.isWorking[pod.UID] {
p.isWorking[pod.UID] = true
podUpdates <- *options
} else {
// if a request to kill a pod is pending, we do not let anything overwrite that request.
update, found := p.lastUndeliveredWorkUpdate[pod.UID]
if !found || update.UpdateType != kubetypes.SyncPodKill {
p.lastUndeliveredWorkUpdate[pod.UID] = *options
}
}
}
func (p *podWorkers) managePodLoop(podUpdates <-chan UpdatePodOptions) {
var lastSyncTime time.Time
for update := range podUpdates {
err := func() error {
podUID := update.Pod.UID
status, err := p.podCache.GetNewerThan(podUID, lastSyncTime)
if err != nil {
p.recorder.Eventf(update.Pod, v1.EventTypeWarning, events.FailedSync, "error determining status: %v", err)
return err
}
err = p.syncPodFn(syncPodOptions{
mirrorPod: update.MirrorPod,
pod: update.Pod,
podStatus: status,
killPodOptions: update.KillPodOptions,
updateType: update.UpdateType,
})
lastSyncTime = time.Now()
return err
}()
// notify the call-back function if the operation succeeded or not
if update.OnCompleteFunc != nil {
update.OnCompleteFunc(err)
}
if err != nil {
// IMPORTANT: we do not log errors here, the syncPodFn is responsible for logging errors
klog.Errorf("Error syncing pod %s (%q), skipping: %v", update.Pod.UID, format.Pod(update.Pod), err)
}
p.wrapUp(update.Pod.UID, err)
}
}
syncPod
上述 podWorker 在 managePodLoop 中调用的 syncPod 方法,其实是 Kubelet 对象的 SyncPod 方法,在文件 pkg/kubelet/kubelet.go 中。
这个方法是真正与 container runtime 层交互的。首先会判断是否是 kill 事件,如果是,直接调用 runtime 的 killPod;然后判断是否可以在节点上运行,这里就是上面讲到的 Kubelet 的准入控制;再判断 CNI 插件是否 ready,如果不 ready,则只在 pod 使用 host network 的时候创建并更新 pod 的 cgroups;接着再判断是否是静态 pod,如果是就创建相应的 mirror pod;然后创建 pod 需要挂载的目录;最后调用 runtime 的 syncPod。整个流程如下所示:
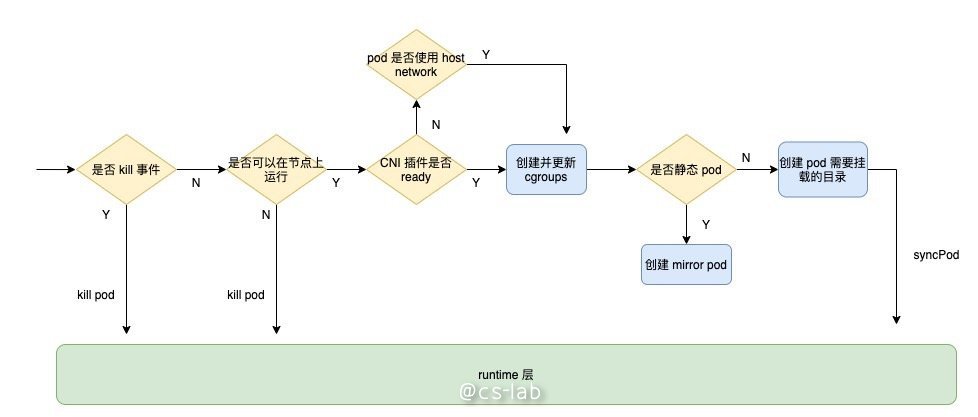
Kubelet 的 syncPod 代码如下,为了理解主流程,我删除了部分优化代码,感兴趣的同学可以自行查阅源码:
func (kl *kubelet) syncPod(o syncPodOptions) error {
// pull out the required options
pod := o.pod
mirrorPod := o.mirrorPod
podStatus := o.podStatus
updateType := o.updateType
// if we want to kill a pod, do it now!
if updateType == kubetypes.SyncPodKill {
...
if err := kl.killPod(pod, nil, podStatus, killPodOptions.PodTerminationGracePeriodSecondsOverride); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToKillPod, "error killing pod: %v", err)
// there was an error killing the pod, so we return that error directly
utilruntime.HandleError(err)
return err
}
return nil
}
...
runnable := kl.canRunPod(pod)
if !runnable.Admit {
...
}
...
// If the network plugin is not ready, only start the pod if it uses the host network
if err := kl.runtimeState.networkErrors(); err != nil && !kubecontainer.IsHostNetworkPod(pod) {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.NetworkNotReady, "%s: %v", NetworkNotReadyErrorMsg, err)
return fmt.Errorf("%s: %v", NetworkNotReadyErrorMsg, err)
}
...
if !kl.podIsTerminated(pod) {
...
if !(podKilled && pod.Spec.RestartPolicy == v1.RestartPolicyNever) {
if !pcm.Exists(pod) {
if err := kl.containerManager.UpdateQOSCgroups(); err != nil {
klog.V(2).Infof("Failed to update QoS cgroups while syncing pod: %v", err)
}
...
}
}
}
// Create Mirror Pod for Static Pod if it doesn't already exist
if kubetypes.IsStaticPod(pod) {
...
}
if mirrorPod == nil || deleted {
node, err := kl.GetNode()
if err != nil || node.DeletionTimestamp != nil {
klog.V(4).Infof("No need to create a mirror pod, since node %q has been removed from the cluster", kl.nodeName)
} else {
klog.V(4).Infof("Creating a mirror pod for static pod %q", format.Pod(pod))
if err := kl.podManager.CreateMirrorPod(pod); err != nil {
klog.Errorf("Failed creating a mirror pod for %q: %v", format.Pod(pod), err)
}
}
}
}
// Make data directories for the pod
if err := kl.makePodDataDirs(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedToMakePodDataDirectories, "error making pod data directories: %v", err)
klog.Errorf("Unable to make pod data directories for pod %q: %v", format.Pod(pod), err)
return err
}
// Volume manager will not mount volumes for terminated pods
if !kl.podIsTerminated(pod) {
// Wait for volumes to attach/mount
if err := kl.volumeManager.WaitForAttachAndMount(pod); err != nil {
kl.recorder.Eventf(pod, v1.EventTypeWarning, events.FailedMountVolume, "Unable to attach or mount volumes: %v", err)
klog.Errorf("Unable to attach or mount volumes for pod %q: %v; skipping pod", format.Pod(pod), err)
return err
}
}
// Fetch the pull secrets for the pod
pullSecrets := kl.getPullSecretsForPod(pod)
// Call the container runtime's SyncPod callback
result := kl.containerRuntime.SyncPod(pod, podStatus, pullSecrets, kl.backOff)
kl.reasonCache.Update(pod.UID, result)
if err := result.Error(); err != nil {
// Do not return error if the only failures were pods in backoff
for _, r := range result.SyncResults {
if r.Error != kubecontainer.ErrCrashLoopBackOff && r.Error != images.ErrImagePullBackOff {
// Do not record an event here, as we keep all event logging for sync pod failures
// local to container runtime so we get better errors
return err
}
}
return nil
}
return nil
}
创建 pod 的整个流程到这里就走到了 runtime 层的 syncPod 部分,下面来看下这里的流程:

流程很清晰,首先计算 pod 的 sandbox 和容器的变化,如果 sandbox 发生了变化,就将 pod kill 掉,再 kill 掉其相关的容器;接着为 pod 创建 sandbox(无论是需要新建的 pod 还是 sandbox 发生变化被删除的 pod);后面就是启动 ephemeral 容器、init 容器以及业务容器。
其中,ephemeral 容器是 k8s v1.16 版本的新特性,该容器在现有 Pod 中临时运行,为了完成用户启动的操作,例如故障排查。
整个代码如下,这里同样为了显示主流程,删除了一些优化代码:
func (m *kubeGenericRuntimeManager) SyncPod(pod *v1.Pod, podStatus *kubecontainer.PodStatus, pullSecrets []v1.Secret, backOff *flowcontrol.Backoff) (result kubecontainer.PodSyncResult) {
// Step 1: Compute sandbox and container changes.
podContainerChanges := m.computePodActions(pod, podStatus)
klog.V(3).Infof("computePodActions got %+v for pod %q", podContainerChanges, format.Pod(pod))
if podContainerChanges.CreateSandbox {
ref, err := ref.GetReference(legacyscheme.Scheme, pod)
if err != nil {
klog.Errorf("Couldn't make a ref to pod %q: '%v'", format.Pod(pod), err)
}
...
}
// Step 2: Kill the pod if the sandbox has changed.
if podContainerChanges.KillPod {
killResult := m.killPodWithSyncResult(pod, kubecontainer.ConvertPodStatusToRunningPod(m.runtimeName, podStatus), nil)
result.AddPodSyncResult(killResult)
...
} else {
// Step 3: kill any running containers in this pod which are not to keep.
for containerID, containerInfo := range podContainerChanges.ContainersToKill {
...
if err := m.killContainer(pod, containerID, containerInfo.name, containerInfo.message, nil); err != nil {
killContainerResult.Fail(kubecontainer.ErrKillContainer, err.Error())
klog.Errorf("killContainer %q(id=%q) for pod %q failed: %v", containerInfo.name, containerID, format.Pod(pod), err)
return
}
}
}
...
// Step 4: Create a sandbox for the pod if necessary.
podSandboxID := podContainerChanges.SandboxID
if podContainerChanges.CreateSandbox {
var msg string
var err error
...
podSandboxID, msg, err = m.createPodSandbox(pod, podContainerChanges.Attempt)
if err != nil {
...
}
klog.V(4).Infof("Created PodSandbox %q for pod %q", podSandboxID, format.Pod(pod))
...
}
...
// Step 5: start ephemeral containers
if utilfeature.DefaultFeatureGate.Enabled(features.EphemeralContainers) {
for _, idx := range podContainerChanges.EphemeralContainersToStart {
start("ephemeral container", ephemeralContainerStartSpec(&pod.Spec.EphemeralContainers[idx]))
}
}
// Step 6: start the init container.
if container := podContainerChanges.NextInitContainerToStart; container != nil {
// Start the next init container.
if err := start("init container", containerStartSpec(container)); err != nil {
return
}
...
}
// Step 7: start containers in podContainerChanges.ContainersToStart.
for _, idx := range podContainerChanges.ContainersToStart {
start("container", containerStartSpec(&pod.Spec.Containers[idx]))
}
return
}
最后再来看一下 sandbox 为何物。在计算机安全领域,沙箱(Sandbox)是一种程序的隔离运行机制,其目的是限制不可信进程的权限。docker 在容器中运用了这种技术,为每个容器创建一个 sandbox,定义了其 cgroup 及各种 namespace,做到容器的隔离;k8s 中每个 pod 共享一个 sandbox,所以同一个 pod 的所有容器才能够互通,且与外界隔离。
我们看一下 Kubelet 为 pod 创建 sandbox 的过程。首先定义 pod 的 DNS 配置、HostName、日志路径以及 sandbox 端口,这些都是 pod 中容器共享的;然后为 pod 定义 linux 配置,包括父亲 cgroup、IPC/Network/Pid namespace、sysctls、Linux 权限;所有都配置好后,才调用 CRI 接口创建 sandbox。整个流程如下:

源代码:
func (m *kubeGenericRuntimeManager) createPodSandbox(pod *v1.Pod, attempt uint32) (string, string, error) {
podSandboxConfig, err := m.generatePodSandboxConfig(pod, attempt)
...
// Create pod logs directory
err = m.osInterface.MkdirAll(podSandboxConfig.LogDirectory, 0755)
...
podSandBoxID, err := m.runtimeService.RunPodSandbox(podSandboxConfig, runtimeHandler)
...
return podSandBoxID, "", nil
}
func (m *kubeGenericRuntimeManager) generatePodSandboxConfig(pod *v1.Pod, attempt uint32) (*runtimeapi.PodSandboxConfig, error) {
podUID := string(pod.UID)
podSandboxConfig := &runtimeapi.PodSandboxConfig{
Metadata: &runtimeapi.PodSandboxMetadata{
Name: pod.Name,
Namespace: pod.Namespace,
Uid: podUID,
Attempt: attempt,
},
Labels: newPodLabels(pod),
Annotations: newPodAnnotations(pod),
}
dnsConfig, err := m.runtimeHelper.GetPodDNS(pod)
...
podSandboxConfig.DnsConfig = dnsConfig
if !kubecontainer.IsHostNetworkPod(pod) {
podHostname, podDomain, err := m.runtimeHelper.GeneratePodHostNameAndDomain(pod)
podHostname, err = util.GetNodenameForKernel(podHostname, podDomain, pod.Spec.SetHostnameAsFQDN)
podSandboxConfig.Hostname = podHostname
}
logDir := BuildPodLogsDirectory(pod.Namespace, pod.Name, pod.UID)
podSandboxConfig.LogDirectory = logDir
portMappings := []*runtimeapi.PortMapping{}
for _, c := range pod.Spec.Containers {
containerPortMappings := kubecontainer.MakePortMappings(&c)
...
}
if len(portMappings) > 0 {
podSandboxConfig.PortMappings = portMappings
}
lc, err := m.generatePodSandboxLinuxConfig(pod)
...
podSandboxConfig.Linux = lc
return podSandboxConfig, nil
}
// generatePodSandboxLinuxConfig generates LinuxPodSandboxConfig from v1.Pod.
func (m *kubeGenericRuntimeManager) generatePodSandboxLinuxConfig(pod *v1.Pod) (*runtimeapi.LinuxPodSandboxConfig, error) {
cgroupParent := m.runtimeHelper.GetPodCgroupParent(pod)
lc := &runtimeapi.LinuxPodSandboxConfig{
CgroupParent: cgroupParent,
SecurityContext: &runtimeapi.LinuxSandboxSecurityContext{
Privileged: kubecontainer.HasPrivilegedContainer(pod),
SeccompProfilePath: v1.SeccompProfileRuntimeDefault,
},
}
sysctls := make(map[string]string)
if utilfeature.DefaultFeatureGate.Enabled(features.Sysctls) {
if pod.Spec.SecurityContext != nil {
for _, c := range pod.Spec.SecurityContext.Sysctls {
sysctls[c.Name] = c.Value
}
}
}
lc.Sysctls = sysctls
if pod.Spec.SecurityContext != nil {
sc := pod.Spec.SecurityContext
if sc.RunAsUser != nil {
lc.SecurityContext.RunAsUser = &runtimeapi.Int64Value{Value: int64(*sc.RunAsUser)}
}
if sc.RunAsGroup != nil {
lc.SecurityContext.RunAsGroup = &runtimeapi.Int64Value{Value: int64(*sc.RunAsGroup)}
}
lc.SecurityContext.NamespaceOptions = namespacesForPod(pod)
if sc.FSGroup != nil {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, int64(*sc.FSGroup))
}
if groups := m.runtimeHelper.GetExtraSupplementalGroupsForPod(pod); len(groups) > 0 {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, groups...)
}
if sc.SupplementalGroups != nil {
for _, sg := range sc.SupplementalGroups {
lc.SecurityContext.SupplementalGroups = append(lc.SecurityContext.SupplementalGroups, int64(sg))
}
}
if sc.SELinuxOptions != nil {
lc.SecurityContext.SelinuxOptions = &runtimeapi.SELinuxOption{
User: sc.SELinuxOptions.User,
Role: sc.SELinuxOptions.Role,
Type: sc.SELinuxOptions.Type,
Level: sc.SELinuxOptions.Level,
}
}
}
return lc, nil
}
总结
Kubelet 的核心工作都是围绕控制循环展开的,而控制循环中借助了 go 的 channel,以 channel 为基础,生产者和消费者协同工作使得控制循环得以运作,从而达到期望状态。


