
目前容器的网络解决方案越来越多,每出现一种新的解决方案,都要为网络方案和不同的容器运行时进行适配,这显然是不合理的,而 CNI 就是为了解决这个问题。
春节假期在家维护「家庭级 Kubernetes 集群」时,萌生了写一个网络插件的想法,于是基于 cni/plugin 仓库已有的轮子,写了 Village Net( https://github.com/zwwhdls/village-net )。以这个网络插件为例,本文着重介绍如何实现一个 CNI 插件。
CNI 工作原理
要了解如何实现一个 CNI 插件,需要先了解 CNI 的工作原理。CNI 是 Container Network Interface 的缩写,是一个接口协议,用于配置容器的网络。容器管理系统提供容器所在的 network namespace 之后,CNI 负责将 network interface 插入到该 network namespace 中,并配置相应的 ip 和路由。
CNI 其实是容器运行时系统和 CNI Plugin 的一个连接桥梁,CNI 将容器的运行时的信息以及网络配置信息传递 Plugin,由各个 Plugin 实现后续工作,所以 CNI Plugin 才是容器网络的具体实现。可以总结为下面这张图:
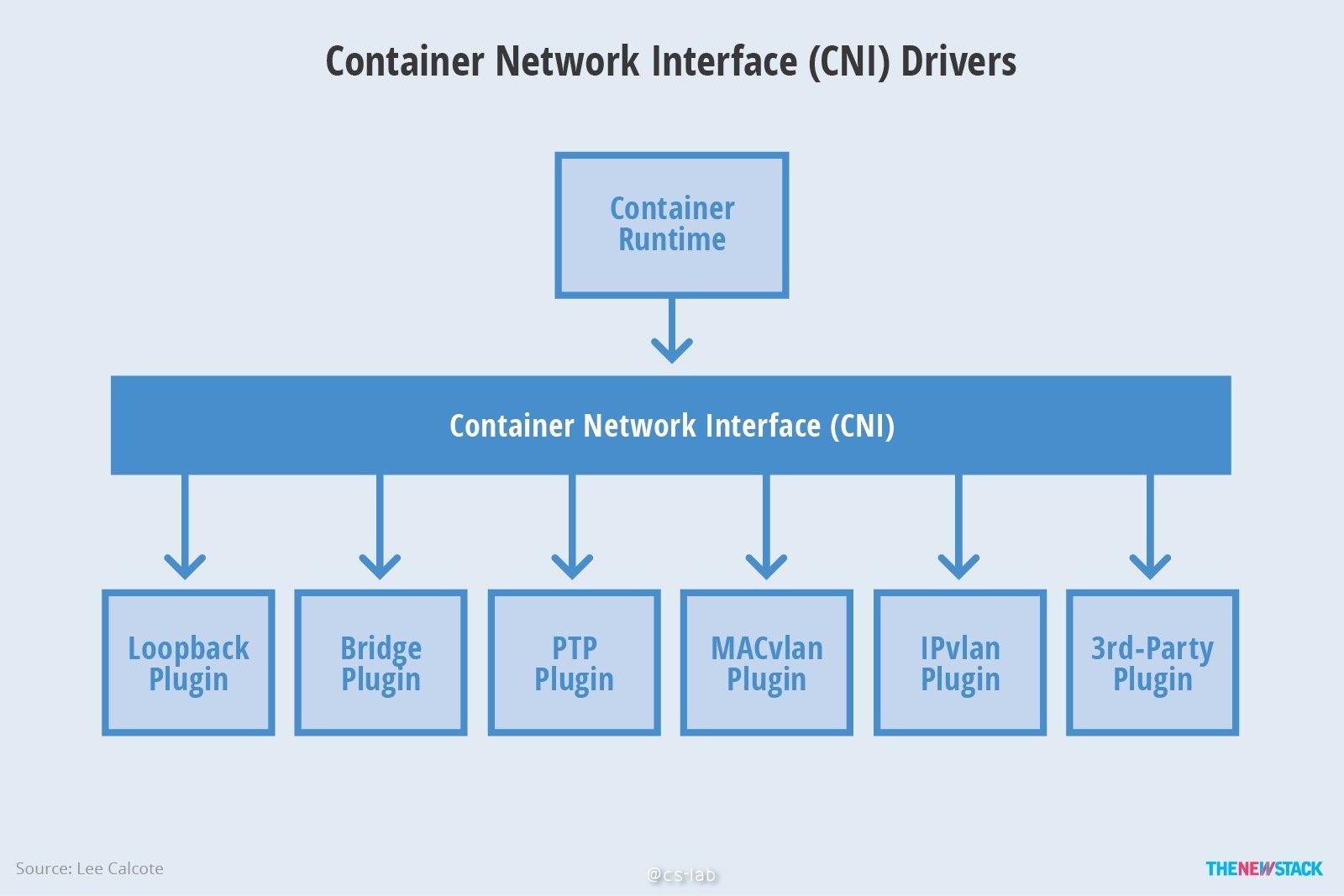
CNI Plugin 是什么
现在我们知道 CNI Plugin 是容器网络的具体实现。在集群里,每个 Plugin 以二进制的形式存在,由 kubelet 通过 CNI 接口来调用每个插件执行。具体的流程如下:
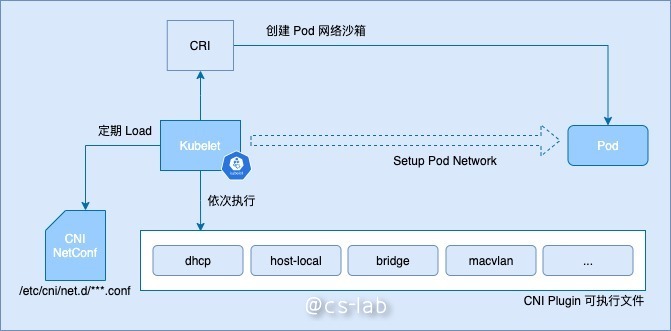
CNI Plugin 可以分为三类:Main、IPAM 和 Meta。其中 Main 和 IPAM 插件相辅相成,完成了为容器创建网络环境的基本工作。
IPAM 插件
IPAM (IP Address Management) 插件主要用来负责分配IP地址。官方提供的可使用插件包括下面几种:
- dhcp:宿主机上运行的守护进程,代表容器发出 DHCP 请求
- host-local:使用提前分配好的 IP 地址段来分配,并在内存中记录 ip 的使用情况
- static:用于为容器分配静态的 IP 地址,主要是调试使用
Main 插件
Main 插件主要用来创建具体的网络设备的二进制文件。官方提供的可使用插件包括下面几种:
- bridge: 在宿主机上创建网桥然后通过 veth pair 的方式连接到容器
- macvlan:虚拟出多个 macvtap,每个 macvtap 都有不同的 mac 地址
- ipvlan:和 macvla n相似,也是通过一个主机接口虚拟出多个虚拟网络接口,不同的是 ipvlan 虚拟出来的是共享 MAC 地址,ip 地址不同
- loopback:lo 设备(将回环接口设置成up)
- ptp:veth pair 设备
- vlan:分配 vlan 设备
- host-device:移动宿主上已经存在的设备到容器中
Meta 插件
由CNI社区维护的内部插件,目前主要包括:
- flannel: 专门为 Flannel 项目提供的插件
- tuning:通过 sysctl 调整网络设备参数的二进制文件
- portmap:通过 iptables 配置端口映射的二进制文件
- bandwidth:使用 Token Bucket Filter (TBF) 来进行限流的二进制文件
- firewall:通过 iptables 或者 firewalled 添加规则控制容器的进出流量
CNI Plugin 的实现
CNI Plugin 的仓库在:https://github.com/containernetworking/plugins 。在里面可以看到每种类型 Plugin 的具体实现。每个 Plugin 都需要实现以下三个方法,再在 main 中注册一下。
func cmdCheck(args *skel.CmdArgs) error {
...
}
func cmdAdd(args *skel.CmdArgs) error {
...
}
func cmdDel(args *skel.CmdArgs) error {
...
}
以 host-local 为例,注册的方法如下,需要指明上面实现的三个方法、支持的版本、以及 Plugin 的名称。
func main() {
skel.PluginMain(cmdAdd, cmdCheck, cmdDel, version.All, bv.BuildString("host-local"))
}
CNI 是什么
了解了 Plugin 的工作原理之后,再来看下 CNI 的具体工作原理。CNI 的仓库在:https://github.com/containernetworking/cni 。本文分析的代码以当前最新版本 v0.8.1 为基准。
社区提供了一个工具 cnitool,是模拟 CNI 接口被调用的工具,可以在一个已存在的 network namespace 中增加或删除网络设备。
先来看下 cnitool 的执行逻辑:
func main() {
...
netconf, err := libcni.LoadConfList(netdir, os.Args[2])
...
netns := os.Args[3]
netns, err = filepath.Abs(netns)
...
// Generate the containerid by hashing the netns path
s := sha512.Sum512([]byte(netns))
containerID := fmt.Sprintf("cnitool-%x", s[:10])
cninet := libcni.NewCNIConfig(filepath.SplitList(os.Getenv(EnvCNIPath)), nil)
rt := &libcni.RuntimeConf{
ContainerID: containerID,
NetNS: netns,
IfName: ifName,
Args: cniArgs,
CapabilityArgs: capabilityArgs,
}
switch os.Args[1] {
case CmdAdd:
result, err := cninet.AddNetworkList(context.TODO(), netconf, rt)
if result != nil {
_ = result.Print()
}
exit(err)
case CmdCheck:
err := cninet.CheckNetworkList(context.TODO(), netconf, rt)
exit(err)
case CmdDel:
exit(cninet.DelNetworkList(context.TODO(), netconf, rt))
}
}
从上面的代码中可以看出,先是从 cni 配置文件中解析出配置 netconf,然后获取 netns、containerId 等信息作为容器的运行时信息传给接口 cninet.AddNetworkList。
接下来看下接口 AddNetworkList 的实现:
// AddNetworkList executes a sequence of plugins with the ADD command
func (c *CNIConfig) AddNetworkList(ctx context.Context, list *NetworkConfigList, rt *RuntimeConf) (types.Result, error) {
var err error
var result types.Result
for _, net := range list.Plugins {
result, err = c.addNetwork(ctx, list.Name, list.CNIVersion, net, result, rt)
if err != nil {
return nil, err
}
}
...
return result, nil
}
显然,该函数的作用就是按顺序执行各个 Plugin 的 addNetwork 操作。再看下 addNetwork 函数:
func (c *CNIConfig) addNetwork(ctx context.Context, name, cniVersion string, net *NetworkConfig, prevResult types.Result, rt *RuntimeConf) (types.Result, error) {
c.ensureExec()
pluginPath, err := c.exec.FindInPath(net.Network.Type, c.Path)
...
newConf, err := buildOneConfig(name, cniVersion, net, prevResult, rt)
...
return invoke.ExecPluginWithResult(ctx, pluginPath, newConf.Bytes, c.args("ADD", rt), c.exec)
}
对每个插件的 addNetwork 操作分为三个部分:
- 首先,调用 FindInPath 函数,根据插件的类型来查找插件的绝对路径;
- 接着,调用 buildOneConfig 函数,从 NetworkList 中提取中当前插件的 NetworkConfig 结构,而其中的 preResult 是上一个插件的执行结果。
- 最后,调用 invoke.ExecPluginWithResult 函数,真正执行插件的 Add 操作。其中 newConf.Bytes 存放 NetworkConfig 结构以及上一个插件的执行结果编码形成的字节流;而 c.args 函数用于构建一个 Args 类型的实例,主要存储容器运行时信息以及执行 CNI 的操作信息。
事实上,invoke.ExecPluginWithResult 仅仅是一个包装函数,里面调用了一下 exec.ExecPlugin 就返回了,这里我们看一下 exec.ExecPlugin 的实现:
func (e *RawExec) ExecPlugin(ctx context.Context, pluginPath string, stdinData []byte, environ []string) ([]byte, error) {
stdout := &bytes.Buffer{}
stderr := &bytes.Buffer{}
c := exec.CommandContext(ctx, pluginPath)
c.Env = environ
c.Stdin = bytes.NewBuffer(stdinData)
c.Stdout = stdout
c.Stderr = stderr
// Retry the command on "text file busy" errors
for i := 0; i <= 5; i++ {
err := c.Run()
...
// All other errors except than the busy text file
return nil, e.pluginErr(err, stdout.Bytes(), stderr.Bytes())
}
...
}
看到这里,我们也就看到了整个 CNI 的核心逻辑,出乎意料的简单,仅仅是 exec 了插件的可执行文件,发生错误的时候重试 5 次。
至此,整个 CNI 的执行流程已经非常清晰了,简而言之,一个 CNI 插件就是一个可执行文件,从配置文件中获取网络的配置信息,从容器运行时获取容器的信息,前者以标准输入的形式,后者以环境变量的形式传给各个插件,最终以配置文件中定义的顺序依次调用各个插件,并且将前一个插件的执行结果包含在配置信息中传给下一个插件。
尽管如此,我们目前熟悉的成熟的网络插件的方案(如 calico),通常都不是依次调用 Plugin,而是只调用 main 插件,在 main 插件中调用 ipam 插件,并当场获取执行结果。
kubelet 如何使用 CNI
了解了 CNI 插件的具体工作原理之后,再来看看 kubelet 如何使用 CNI 插件。
kubelet 在创建 pod 的时候,会调用 CNI 插件为 pod 创建网络环境。源码如下,可以看到 kubelet 在 SetUpPod 函数(pkg/kubelet/dockershim/network/cni/cni.go)中调用了 plugin.addToNetwork 函数:
func (plugin *cniNetworkPlugin) SetUpPod(namespace string, name string, id kubecontainer.ContainerID, annotations, options map[string]string) error {
if err := plugin.checkInitialized(); err != nil {
return err
}
netnsPath, err := plugin.host.GetNetNS(id.ID)
...
if plugin.loNetwork != nil {
if _, err = plugin.addToNetwork(cniTimeoutCtx, plugin.loNetwork, name, namespace, id, netnsPath, annotations, options); err != nil {
return err
}
}
_, err = plugin.addToNetwork(cniTimeoutCtx, plugin.getDefaultNetwork(), name, namespace, id, netnsPath, annotations, options)
return err
}
再来看看 addToNetwork 函数,该函数首先会去构建 pod 的运行时信息,再读取 CNI 插件的网络配置信息,即 /etc/cni/net.d 目录下的配置文件。组装好 plugin 需要的参数后调用 cni 的接口 cniNet.AddNetworkList。源码如下:
func (plugin *cniNetworkPlugin) addToNetwork(ctx context.Context, network *cniNetwork, podName string, podNamespace string, podSandboxID kubecontainer.ContainerID, podNetnsPath string, annotations, options map[string]string) (cnitypes.Result, error) {
rt, err := plugin.buildCNIRuntimeConf(podName, podNamespace, podSandboxID, podNetnsPath, annotations, options)
...
pdesc := podDesc(podNamespace, podName, podSandboxID)
netConf, cniNet := network.NetworkConfig, network.CNIConfig
...
res, err := cniNet.AddNetworkList(ctx, netConf, rt)
...
return res, nil
}
模拟 CNI 的执行过程
在了解了整个 CNI 的执行流程后,我们模拟一下 CNI 的执行过程。我们用 cnitool 工具,main 插件选择 bridge,ipam 插件选择 host-local,来模拟容器网络配置。
编译 plugins
首先将 CNI Plugin 编译成可执行文件,可以执行运行官方仓库中的 build_linux.sh 脚本:
$ mkdir -p $GOPATH/src/github.com/containernetworking/plugins
$ git clone https://github.com/containernetworking/plugins.git $GOPATH/src/github.com/containernetworking/plugins
$ cd $GOPATH/src/github.com/containernetworking/plugins
$ ./build_linux.sh
$ ls
bandwidth dhcp flannel host-local loopback portmap sbr tuning village-ipam vrf
bridge firewall host-device ipvlan macvlan ptp static village vlan
创建网络配置文件
接着创建我们自己的网络配置文件,main 插件选择 bridge,ipam 插件选择 host-local,并指定可用 ip 段。
$ mkdir -p /etc/cni/net.d
$ cat >/etc/cni/net.d/10-hdlsnet.conf <<EOF
{
"cniVersion": "0.2.0",
"name": "hdls-net",
"type": "bridge",
"bridge": "cni0",
"isGateway": true,
"ipMasq": true,
"ipam": {
"type": "host-local",
"subnet": "10.22.0.0/16",
"routes": [
{ "dst": "0.0.0.0/0" }
]
}
}
EOF
$ cat >/etc/cni/net.d/99-loopback.conf <<EOF
{
"cniVersion": "0.2.0",
"name": "lo",
"type": "loopback"
}
EOF
创建 network namespace
$ ip netns add hdls
执行 cnitool 的 add
最后将 CNI_PATH 指定为上面编译好的插件可执行文件的路径,再运行官方仓库的 cnitool 工具:
$ mkdir -p $GOPATH/src/github.com/containernetworking/cni
$ git clone https://github.com/containernetworking/cni.git $GOPATH/src/github.com/containernetworking/cni
$ export CNI_PATH=$GOPATH/src/github.com/containernetworking/plugins/bin
$ go run cnitool.go add hdls-net /var/run/netns/hdls
\{
"cniVersion": "0.2.0",
"ip4": {
"ip": "10.22.0.2/16",
"gateway": "10.22.0.1",
"routes": [
{
"dst": "0.0.0.0/0"
}
]
},
"dns": {}
}#
结果表面为这个 network namespace hdls-net 分配的 ip 为 10.22.0.2,其实也就是说我们手动创建的容器 ip 为 10.22.0.2。
验证
获得了容器的 ip 后,检验是可以 ping 通的,用 nsenter 命令进入到容器的 namespace 中也可以发现该容器的默认网络设备 eth0 也创建出来了:
$ ping 10.22.0.2
PING 10.22.0.2 (10.22.0.2) 56(84) bytes of data.
64 bytes from 10.22.0.2: icmp_seq=1 ttl=64 time=0.039 ms
64 bytes from 10.22.0.2: icmp_seq=2 ttl=64 time=0.046 ms
64 bytes from 10.22.0.2: icmp_seq=3 ttl=64 time=0.042 ms
64 bytes from 10.22.0.2: icmp_seq=4 ttl=64 time=0.073 ms
^C
--- 10.22.0.2 ping statistics ---
4 packets transmitted, 4 received, 0% packet loss, time 3000ms
rtt min/avg/max/mdev = 0.039/0.050/0.073/0.013 ms
$ nsenter --net=/var/run/netns/hdls bash
[root@node-3 ~]# ip l
1: lo: <LOOPBACK> mtu 65536 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
3: eth0@if5: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether be:6b:0c:93:3a:75 brd ff:ff:ff:ff:ff:ff link-netnsid 0
[root@node-3 ~]#
最后我们再来检查一下宿主机的网络设备,发现和容器的 eth0 相对应的 veth 设备对也创建出来了:
$ ip l
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 00:0c:29:9a:04:8d brd ff:ff:ff:ff:ff:ff
3: docker0: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 qdisc noqueue state DOWN mode DEFAULT group default
link/ether 02:42:22:86:98:d9 brd ff:ff:ff:ff:ff:ff
4: cni0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default qlen 1000
link/ether 76:32:56:61:e4:f5 brd ff:ff:ff:ff:ff:ff
5: veth3e674876@if3: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master cni0 state UP mode DEFAULT group default
link/ether 62:b3:06:15:f9:39 brd ff:ff:ff:ff:ff:ff link-netnsid 0
Village Net
之所以选择 Village Net 作为插件的名字,是希望通过 macvlan 实现一个基于二层的网络插件。而对于一个二层网络来说,内部通讯像极了一个小村庄,通讯基本靠吼(arp),当然还有村通网的含义,虽然简陋,但足够好用。
工作原理
选择 macvlan 实现网络插件的原因在于,对于一个「家庭级 Kubernetes 集群」来说,节点的数目并不多,但是服务并不少,只能通过端口映射(nodeport)对服务进行区分,而因为所有的机器本来就在同一个交换机上,IP 相对富裕,macvlan/ipvlan 都是简单且好实现的方案。考虑到基于 mac 可以利用 dhcp 服务,甚至可以基于 mac 对 pod 的 ip 进行固定,因此便尝试使用 macvlan 实现网络插件。
但是 macvlan 在跨 net namespace 中存在不少问题,比如存在独立 net namespace 时,流量会跨过 host 的协议栈,导致了基于 iptables/ipvs 的 cluster ip 无法正常工作。
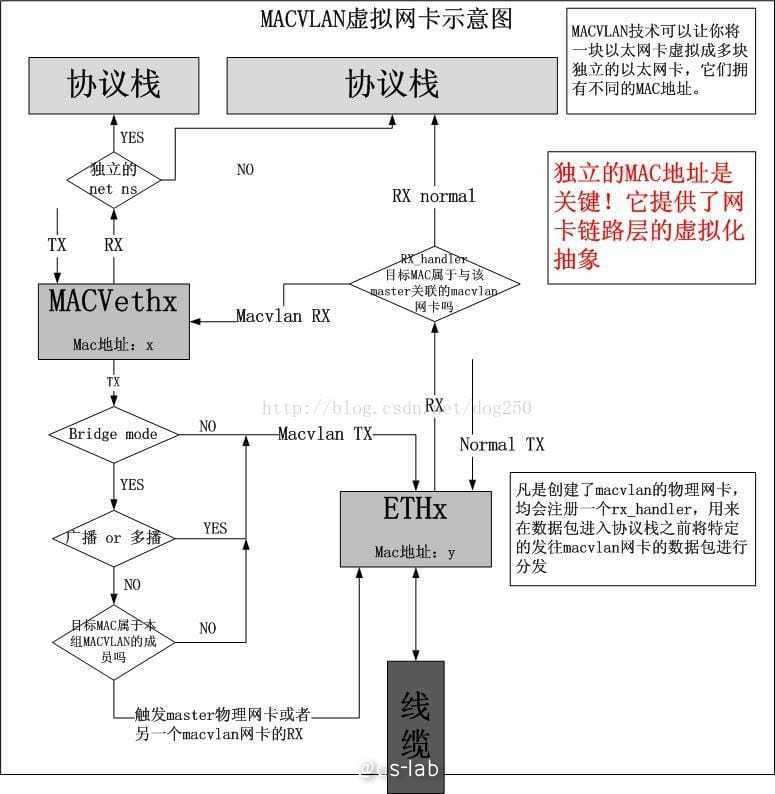
当然,也正是相同原因,只是使用 macvlan 时,宿主机和容器的网络是不互通的,不过可以创建额外的 macvlan bridge 解决。
为了解决 cluster ip 无法正常工作的问题,便舍弃了只是用 macvlan 的念头,使用多网络接口进行组网。

每个 Pod 都有两个网络接口,一个是基于 bridge 的 eth0,并作为默认网关,同时,在宿主机上会添加相关路由以确保可以跨节点通信。第二个接口是 bridge 模式的 macvlan,并为这个设备分配宿主机网段的 ip。
工作流程
和前面提到的 CNI 的工作流程一致,village net 也是分为 main 插件和 ipam 插件。

ipam 的主要任务是基于配置从两个网段中个分配出一个可用 IP,main 插件是基于两个网段的 IP 创建出 bridge、veth、macvlan 设备,并进行配置。
最后
Village Net 的实现还是比较简单,甚至还需要部分手动操作,比如 bridge 的路由部分。但是功能上基本达到预期,而且对 cni 的坑完整的梳理了一遍。cni 本身并不复杂,但是有很多细节是在一开始做的时候没有考虑到的,甚至最后只是通过了若干 workaround 绕过。如果后面还有时间和精力放在网络插件上,再考虑如何优化。<( ̄▽ ̄)/


