
本文基于对 Kubernetes v1.16 的源码阅读,通过流程图描述 Deployment Controller 的工作流程,但也包含相关代码以供参考
上一篇文章《Kubernetes Controller Manager 工作原理》讲解了 Controller Manager 是怎么管理 Controller 的,我们知道 Controller 只需要实现相关事件 handler,无须再关心上层逻辑。本文将基于这篇文章,介绍 Deployment Controller 在接收到来自 Informer 的事件后,做了哪些工作。
Deployment 与控制器模式
在 K8s 中,pod 是最小的资源单位,而 pod 的副本管理是通过 ReplicaSet(RS) 实现的;而 deployment 实则是基于 RS 做了更上层的工作。
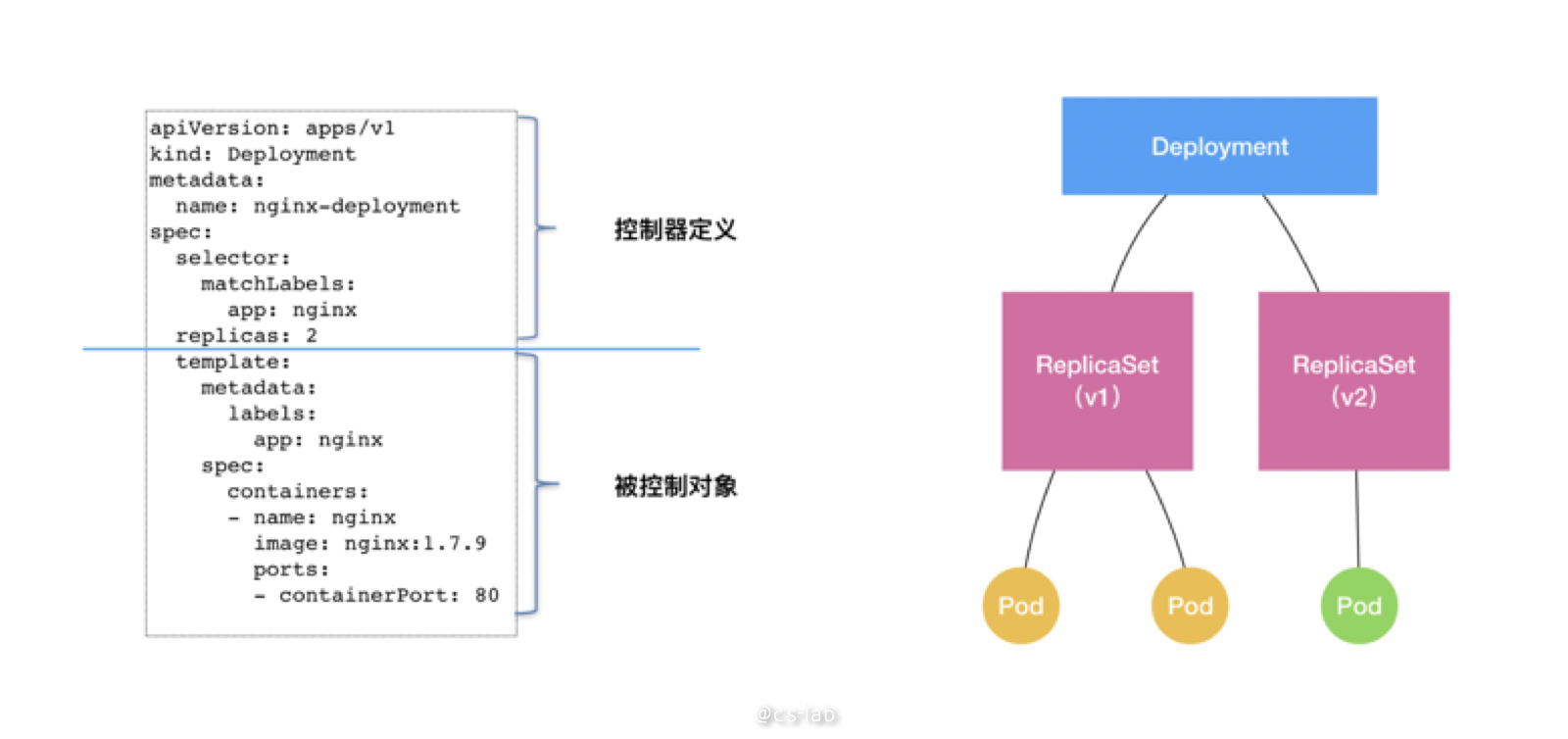
这就是 Kubernetes 的控制器模式,顶层资源通过控制下层资源,来拓展新能力。deployment 并没有直接对 pod 进行管理,是通过管理 rs 来实现对 pod 的副本控制。deployment 通过对 rs 的控制实现了版本管理:每次发布对应一个版本,每个版本有一个 rs,在注解中标识版本号,而 rs 再每次根据 pod template 和副本数运行相应的 pod。deployment 只需要保证任何情况下 rs 的状态都在预期,rs 保证任何情况下 pod 的状态都在预期。
K8s 是怎么管理 Deployment 的
了解了 deployment 这一资源在 K8s 中的定位,我们再来看下这个资源如何达到预期状态。
Kubernetes 的 API 和控制器都是基于水平触发的,可以促进系统的自我修复和周期协调。
水平触发这个概念来自硬件的中断,中断可以是水平触发,也可以是边缘触发:
- 水平触发 : 系统仅依赖于当前状态。即使系统错过了某个事件(可能因为故障挂掉了),当它恢复时,依然可以通过查看信号的当前状态来做出正确的响应。
- 边缘触发 : 系统不仅依赖于当前状态,还依赖于过去的状态。如果系统错过了某个事件(“边缘”),则必须重新查看该事件才能恢复系统。
Kubernetes 水平触发的 API 实现方式是:控制器监视资源对象的实际状态,并与对象期望的状态进行对比,然后调整实际状态,使之与期望状态相匹配。
水平触发的 API 也叫声明式 API,而监控 deployment 资源对象并确定符合预期的控制器就是 deployment controller,对应的 rs 的控制器就是 rs controller。
Deployment Controller
架构
首先看看 DeploymentController 在 K8s 中的定义:
type DeploymentController struct {
rsControl controller.RSControlInterface
client clientset.Interface
eventRecorder record.EventRecorder
syncHandler func(dKey string) error
enqueueDeployment func(deployment *apps.Deployment)
dLister appslisters.DeploymentLister
rsLister appslisters.ReplicaSetLister
podLister corelisters.PodLister
dListerSynced cache.InformerSynced
rsListerSynced cache.InformerSynced
podListerSynced cache.InformerSynced
queue workqueue.RateLimitingInterface
}
主要包括几大块内容:
-
rsControl是一个ReplicaSet Controller的工具,用来对 rs 进行认领和弃养工作; -
client就是与 APIServer 通信的 client; -
eventRecorder用来记录事件; -
syncHandler用来处理 deployment 的同步工作; -
enqueueDeployment是一个将 deployment 入 queue 的方法; -
dLister、rsLister、podLister分别用来从shared informer store中获取 资源的方法; -
dListerSynced、rsListerSynced、podListerSynced分别是用来标识shared informer store中是否同步过; -
queue就是 workqueue,deployment、replicaSet、pod 发生变化时,都会将对应的 deployment 推入这个 queue,syncHandler()方法统一从 workqueue 中处理 deployment。
工作流程
接下来看看 deployment controller 的工作流程。
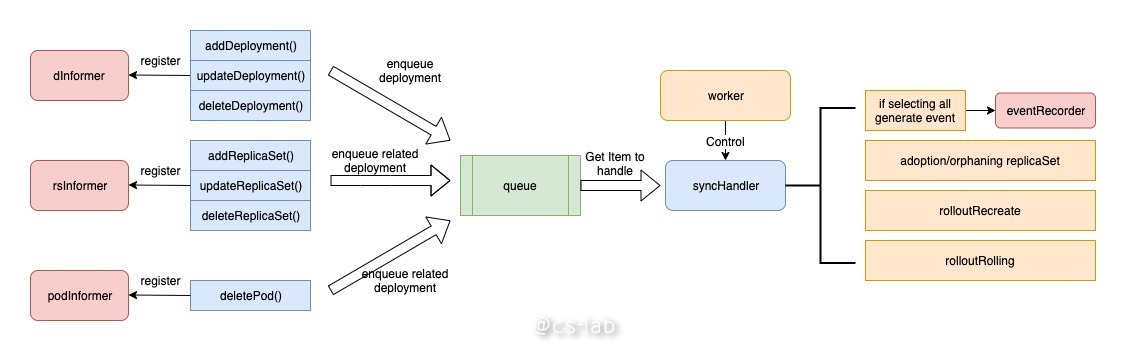
deployment controller 利用了 informer 的工作能力,实现了资源的监听,同时与其他 controller 协同工作。主要使用了三个 shared informer —— deployment informer、rs informer、pod informer。
首先 deployment controller 会向三个 shared informer 中注册钩子函数,三个钩子函数会在相应事件到来时,将相关的 deployment 推进 workqueue 中。
deployment controller 启动时会有一个 worker 来控制 syncHandler 函数,实时地将 workqueue 中的 item 推出,根据 item 来执行任务。主要包括:领养和弃养 rs、向 eventRecorder 分发事件、根据升级策略决定如何处理下级资源。
workqueue
首先看看 workqueue,这其实是用来辅助 informer 对事件进行分发的队列。整个流程可以梳理为下图。
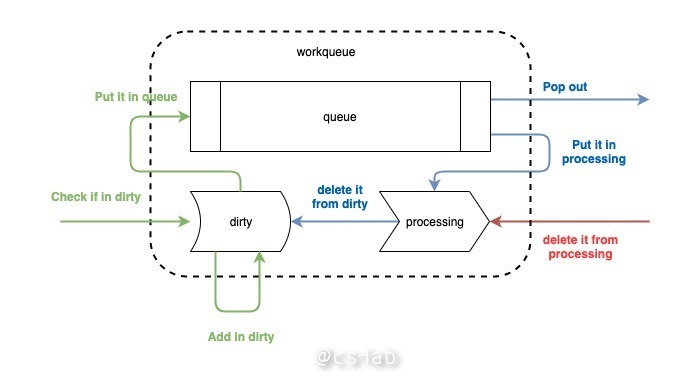
可以看到,workqueue 分为了三个部分,一是一个先入先出的队列,由切片来实现;还有两个是名为 dirty 和 processing 的 map。整个工作流程分为三个动作,分别为 add、get、done。
add 是将消息推入队列。消息时从 informer 过来的,其实过来的消息并不是事件全部,而是资源 key,即 namespace/name,以这种形式通知业务逻辑有资源的变更事件过来了,需要拿着这个 key 去 indexer 中获取具体资源。如上图绿色的过程所示,在消息进行之后,先检查 dirty 中是否存在,若已存在,不做任何处理,表明事件已经在队列中,不需要重复处理;若 dirty 中不存在,则将该 key 存入 dirty 中(将其作为 map 的键,值为空结构体),再推入队列一份。
get 是 handle 函数从队列中获取 key 的过程。将 key 从队列中 pop 出来的同时,会将其放入 processing 中,并删除其在 dirty 的索引。这一步的原因是将 item 放入 processing 中标记其正在被处理,同时从 dirty 中删除则不影响后面的事件入队列。
done 则是 handle 在处理完 key 之后,必须执行的一步,相当于给 workqueue 发一个 ack,表明我已经处理完毕,该动作仅仅将其从 processing 中删除。
有了这个小而美的先入先出的队列,我们就可以避免资源的多个事件发生时,从 indexer 中重复获取资源的事情发生了。下面来梳理 deployment controller 的具体流程。
replicaSet 的认领和弃养过程
在 deployment controller 的工作流程中,可以注意到除了 deployment 的三个钩子函数,还有 rs 和 pod 的钩子函数,在 rs 的三个钩子函数中,涉及到了 deployment 对 rs 的领养和弃养过程。
rs 认亲
首先来看 rs 的认亲过程:
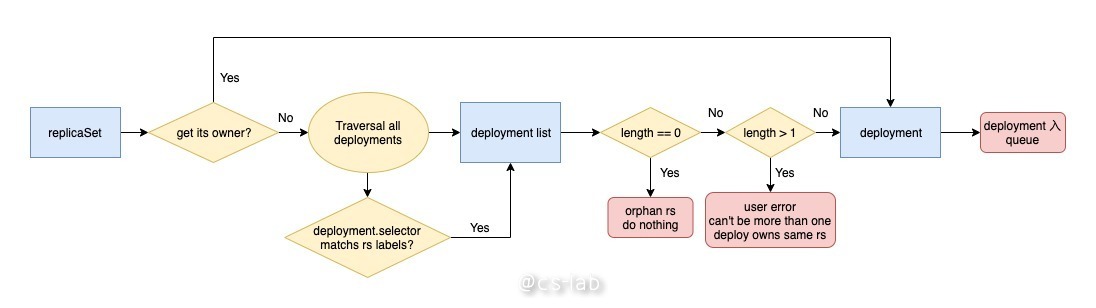
在 rs 的三个钩子函数中,都会涉及到认亲的过程。
当监听到 rs 的变化后,会根据 rs 的 ownerReferences 字段找到对应的 deployment 入 queue;若该字段为空,意味着这是个孤儿 rs,启动 rs 认亲机制。
认亲过程首先是遍历所有的 deployment,判断 deployment 的 selector 是否与当前 rs 的 labels 相匹配,找到所有与之匹配的 deployment。
然后判断总共有多少个 deployment,若为 0 个,就直接返回,没有人愿意认领,什么都不做,认领过程结束;若大于 1 个,抛错出去,因为这是不正常的行为,不允许多个 deployment 同时拥有同一个 rs;若有且仅有一个 deployment 与之匹配,那么就找到了愿意领养的 deployment,将其入 queue。
addReplicaSet() 和 updateReplicaSet() 的认领过程类似,这里只展示 addReplicaSet() 的代码:
func (dc *DeploymentController) addReplicaSet(obj interface{}) {
rs := obj.(*apps.ReplicaSet)
if rs.DeletionTimestamp != nil {
dc.deleteReplicaSet(rs)
return
}
if controllerRef := metav1.GetControllerOf(rs); controllerRef != nil {
d := dc.resolveControllerRef(rs.Namespace, controllerRef)
if d == nil {
return
}
klog.V(4).Infof("ReplicaSet %s added.", rs.Name)
dc.enqueueDeployment(d)
return
}
ds := dc.getDeploymentsForReplicaSet(rs)
if len(ds) == 0 {
return
}
klog.V(4).Infof("Orphan ReplicaSet %s added.", rs.Name)
for _, d := range ds {
dc.enqueueDeployment(d)
}
}
deployment 领养和弃养
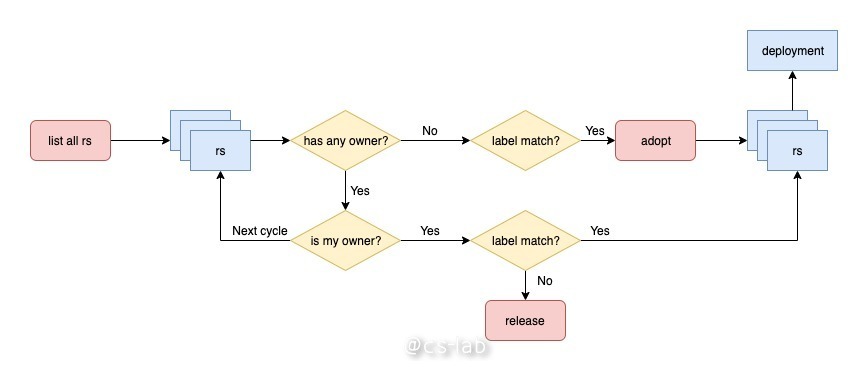
deployment 对 rs 的领养和弃养过程,是发生在从 workqueue 中处理 item 的过程,也是找到当前 deployment 拥有的所有 rs 的过程。
该过程会轮询所有的 rs,如果有 owner 且是当前 deployment,再判断 label 是否满足 deployment 的 selector,满足则列入结果;若不满足,启动弃养机制,仅仅将 rs 的 ownerReferences 删除,使其成为孤儿,不做其他事情。这也是为什么修改了 deployment 的 selector 之后,会多一个 replicas!=0 的 rs 的原因。
如果 rs 没有 owner,是个孤儿,判断 label 是否满足 deployment 的 selector,满足条件,则启动领养机制,将其 ownerReferences 设置为当前 deployment,再列入结果。
下面是整个过程的源码:
func (m *BaseControllerRefManager) ClaimObject(obj metav1.Object, match func(metav1.Object) bool, adopt, release func(metav1.Object) error) (bool, error) {
controllerRef := metav1.GetControllerOf(obj)
if controllerRef != nil {
if controllerRef.UID != m.Controller.GetUID() {
return false, nil
}
if match(obj) {
return true, nil
}
if m.Controller.GetDeletionTimestamp() != nil {
return false, nil
}
if err := release(obj); err != nil {
if errors.IsNotFound(err) {
return false, nil
}
return false, err
}
return false, nil
}
if m.Controller.GetDeletionTimestamp() != nil || !match(obj) {
return false, nil
}
if obj.GetDeletionTimestamp() != nil {
return false, nil
}
if err := adopt(obj); err != nil {
if errors.IsNotFound(err) {
return false, nil
}
return false, err
}
return true, nil
}
领养和弃养的函数:
func (m *ReplicaSetControllerRefManager) AdoptReplicaSet(rs *apps.ReplicaSet) error {
if err := m.CanAdopt(); err != nil {
return fmt.Errorf("can't adopt ReplicaSet %v/%v (%v): %v", rs.Namespace, rs.Name, rs.UID, err)
}
addControllerPatch := fmt.Sprintf(
`{"metadata":{"ownerReferences":[{"apiVersion":"%s","kind":"%s","name":"%s","uid":"%s","controller":true,"blockOwnerDeletion":true}],"uid":"%s"}}`,
m.controllerKind.GroupVersion(), m.controllerKind.Kind,
m.Controller.GetName(), m.Controller.GetUID(), rs.UID)
return m.rsControl.PatchReplicaSet(rs.Namespace, rs.Name, []byte(addControllerPatch))
}
func (m *ReplicaSetControllerRefManager) ReleaseReplicaSet(replicaSet *apps.ReplicaSet) error {
klog.V(2).Infof("patching ReplicaSet %s_%s to remove its controllerRef to %s/%s:%s",
replicaSet.Namespace, replicaSet.Name, m.controllerKind.GroupVersion(), m.controllerKind.Kind, m.Controller.GetName())
deleteOwnerRefPatch := fmt.Sprintf(`{"metadata":{"ownerReferences":[{"$patch":"delete","uid":"%s"}],"uid":"%s"}}`, m.Controller.GetUID(), replicaSet.UID)
err := m.rsControl.PatchReplicaSet(replicaSet.Namespace, replicaSet.Name, []byte(deleteOwnerRefPatch))
if err != nil {
if errors.IsNotFound(err) {
return nil
}
if errors.IsInvalid(err) {
return nil
}
}
return err
}
rolloutRecreate
如果 deployment 的更新策略是 Recreate,其过程是将旧的 pod 删除,再启动新的 pod。具体过程如下:
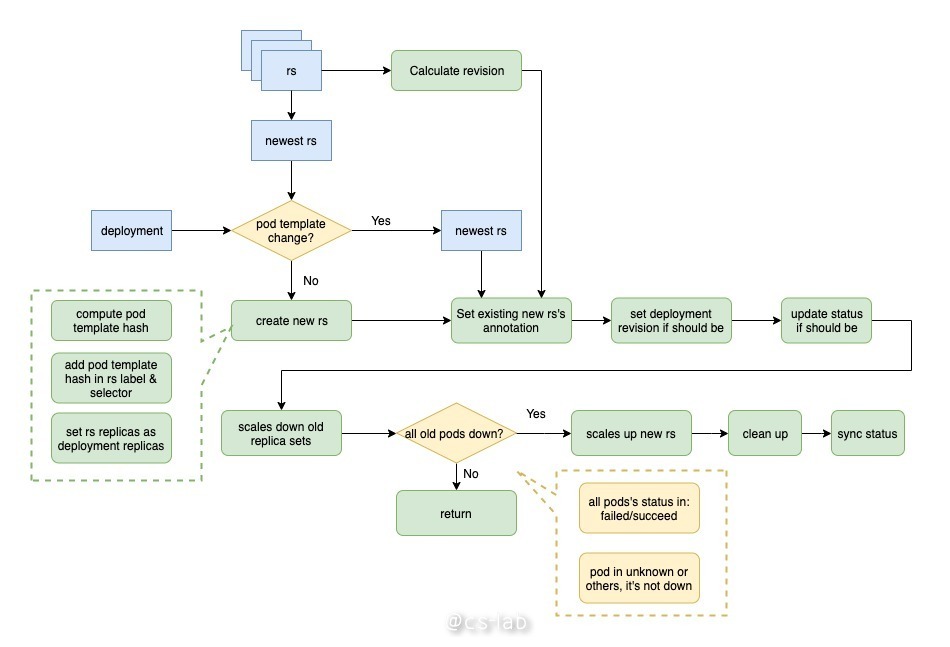
首先根据上一步 rs 的领养和弃养过程,获得当前 deployment 的所有 rs,排序找出最新的 rs,将其 pod template 与 deployment 的 pod template 比较,若不一致需要创建新的 rs;
创建新的 rs 的过程为:计算当前 deployment 的 pod template 的 hash 值,将其增加至 rs label 及 selector 中;
对所有旧的 rs 计算出最大的 revision,将其加一,作为新 rs 的 revision,为新的 rs 设置如下注解:
"deployment.kubernetes.io/revision"
"deployment.kubernetes.io/desired-replicas"
"deployment.kubernetes.io/max-replicas"
如果当前 deployment 的 revision 不是最新,将其设为最新;如果需要更新状态,则更新其状态;
将旧的 rs 进行降级,即将其副本数设为 0;
判断当前所有旧的 pod 是否停止,判断条件为 pod 状态为 failed 或 succeed,unknown 或其他所有状态都不是停止状态;若并非所有 pod 都停止了,则退出本次操作,下一个循环再处理;
若所有 pod 都停止了,将新的 rs 进行升级,即将其副本数置为 deployment 的副本数;
最后进行清理工作,比如旧的 rs 数过多时,删除多余的 rs 等。
下面是 rolloutRecreate 的源代码:
func (dc *DeploymentController) rolloutRecreate(d *apps.Deployment, rsList []*apps.ReplicaSet, podMap map[types.UID][]*v1.Pod) error {
newRS, oldRSs, err := dc.getAllReplicaSetsAndSyncRevision(d, rsList, false)
if err != nil {
return err
}
allRSs := append(oldRSs, newRS)
activeOldRSs := controller.FilterActiveReplicaSets(oldRSs)
scaledDown, err := dc.scaleDownOldReplicaSetsForRecreate(activeOldRSs, d)
if err != nil {
return err
}
if scaledDown {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
if oldPodsRunning(newRS, oldRSs, podMap) {
return dc.syncRolloutStatus(allRSs, newRS, d)
}
if newRS == nil {
newRS, oldRSs, err = dc.getAllReplicaSetsAndSyncRevision(d, rsList, true)
if err != nil {
return err
}
allRSs = append(oldRSs, newRS)
}
if _, err := dc.scaleUpNewReplicaSetForRecreate(newRS, d); err != nil {
return err
}
if util.DeploymentComplete(d, &d.Status) {
if err := dc.cleanupDeployment(oldRSs, d); err != nil {
return err
}
}
return dc.syncRolloutStatus(allRSs, newRS, d)
}
rolloutRolling
如果 deployment 的更新策略是 Recreate,其过程是将旧的 pod 删除,再启动新的 pod。具体过程如下:
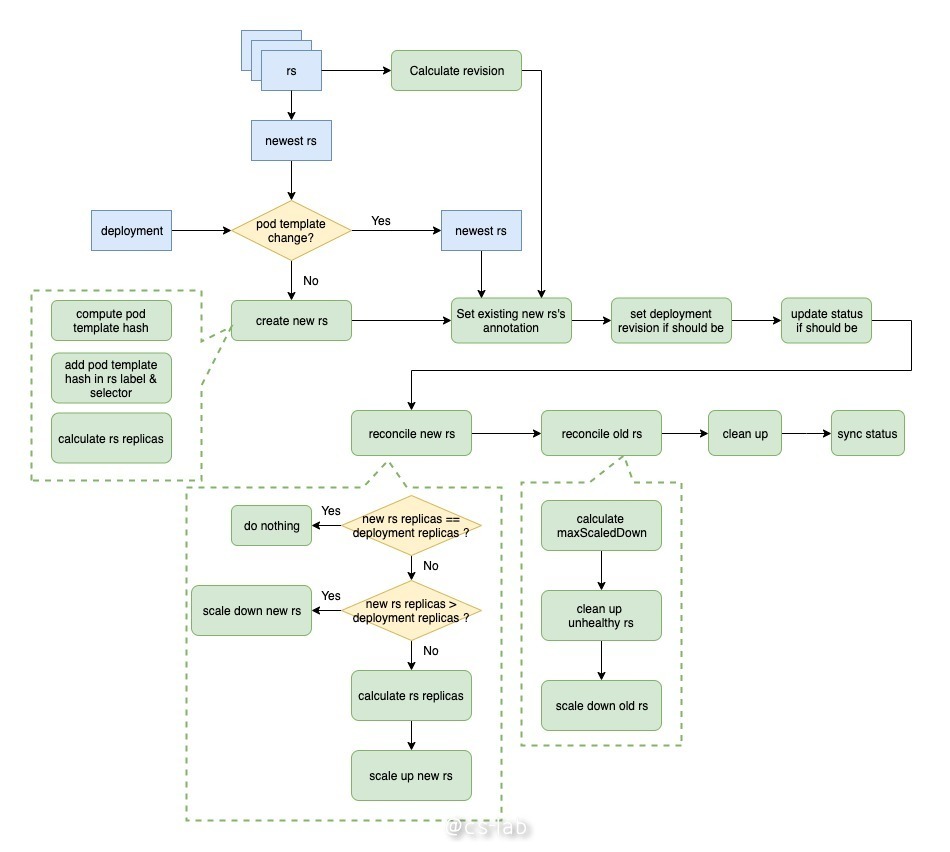
从上图可以看到,从开始到创建新的 rs 的过程与 rolloutRecreate 过程一致,唯一区别在于,设置新 rs 副本数的过程。在 rolloutRolling 的过程中,新的 rs 的副本数为 deploy.replicas + maxSurge - currentPodCount。代码如下:
func NewRSNewReplicas(deployment *apps.Deployment, allRSs []*apps.ReplicaSet, newRS *apps.ReplicaSet) (int32, error) {
switch deployment.Spec.Strategy.Type {
case apps.RollingUpdateDeploymentStrategyType:
// Check if we can scale up.
maxSurge, err := intstrutil.GetValueFromIntOrPercent(deployment.Spec.Strategy.RollingUpdate.MaxSurge, int(*(deployment.Spec.Replicas)), true)
if err != nil {
return 0, err
}
// Find the total number of pods
currentPodCount := GetReplicaCountForReplicaSets(allRSs)
maxTotalPods := *(deployment.Spec.Replicas) + int32(maxSurge)
if currentPodCount >= maxTotalPods {
// Cannot scale up.
return *(newRS.Spec.Replicas), nil
}
// Scale up.
scaleUpCount := maxTotalPods - currentPodCount
// Do not exceed the number of desired replicas.
scaleUpCount = int32(integer.IntMin(int(scaleUpCount), int(*(deployment.Spec.Replicas)-*(newRS.Spec.Replicas))))
return *(newRS.Spec.Replicas) + scaleUpCount, nil
case apps.RecreateDeploymentStrategyType:
return *(deployment.Spec.Replicas), nil
default:
return 0, fmt.Errorf("deployment type %v isn't supported", deployment.Spec.Strategy.Type)
}
}
然后到了增减新旧 rs 副本数的过程。主要为先 scale up 新 rs,再 scale down 旧 rs。scale up 新 rs 的过程与上述一致;scale down 旧 rs 的过程为先计算一个最大 scale down 副本数,若小于 0 则不做任何操作;然后在 scale down 的时候做了一个优化,先 scale down 不正常的 rs,可以保证先删除那些不健康的副本;最后如果还有余额,再 scale down 正常的 rs。
每次 scale down 的副本数为 allAvailablePodCount - minAvailable,即 allAvailablePodCount - (deploy.replicas - maxUnavailable)。代码如下:
func (dc *DeploymentController) scaleDownOldReplicaSetsForRollingUpdate(allRSs []*apps.ReplicaSet, oldRSs []*apps.ReplicaSet, deployment *apps.Deployment) (int32, error) {
maxUnavailable := deploymentutil.MaxUnavailable(*deployment)
// Check if we can scale down.
minAvailable := *(deployment.Spec.Replicas) - maxUnavailable
// Find the number of available pods.
availablePodCount := deploymentutil.GetAvailableReplicaCountForReplicaSets(allRSs)
if availablePodCount <= minAvailable {
// Cannot scale down.
return 0, nil
}
klog.V(4).Infof("Found %d available pods in deployment %s, scaling down old RSes", availablePodCount, deployment.Name)
sort.Sort(controller.ReplicaSetsByCreationTimestamp(oldRSs))
totalScaledDown := int32(0)
totalScaleDownCount := availablePodCount - minAvailable
for _, targetRS := range oldRSs {
if totalScaledDown >= totalScaleDownCount {
// No further scaling required.
break
}
if *(targetRS.Spec.Replicas) == 0 {
// cannot scale down this ReplicaSet.
continue
}
// Scale down.
scaleDownCount := int32(integer.IntMin(int(*(targetRS.Spec.Replicas)), int(totalScaleDownCount-totalScaledDown)))
newReplicasCount := *(targetRS.Spec.Replicas) - scaleDownCount
if newReplicasCount > *(targetRS.Spec.Replicas) {
return 0, fmt.Errorf("when scaling down old RS, got invalid request to scale down %s/%s %d -> %d", targetRS.Namespace, targetRS.Name, *(targetRS.Spec.Replicas), newReplicasCount)
}
_, _, err := dc.scaleReplicaSetAndRecordEvent(targetRS, newReplicasCount, deployment)
if err != nil {
return totalScaledDown, err
}
totalScaledDown += scaleDownCount
}
return totalScaledDown, nil
}
总结
因为 Kubernetes 采用声明式 API,因此对于 Controller 来说,所做的事情就是根据当前事件计算一个预期的状态,并判断当前实际的状态是否满足预期的状态,如果不满足,则采取行动使其靠拢。
本文通过对 Deployment Controller 的工作流程进行分析,虽然做的事情比较繁琐,但是其所做的事情都是围绕 “向预期靠拢” 这个目标展开的。
希望这两篇文章能让你一窥豹斑,了解 Kubernetes Controller Manager 大致的工作流程和实现方式。


