
如果说 Deployment、DaemonSet 等资源为 Kubernetes 承担了长时间、在线计算的能力,那么定时、短期、甚至一次性的离线计算能力,便是 Job 和 CronJob 所承担的事情。
Job
Job 其实就是根据定义起一个或多个 pod 来执行任务,pod 执行完退出后,这个 Job 就完成了。所以 Job 又称为 Batch Job ,即计算业务或离线业务。
Job 使用方法
Job 的 YAML 定义与 Deployment 十分相似。与 Deployment 不同的是,Job 不需要定义 spec.selector 来指定需要控制的 pod,看个例子:
apiVersion: batch/v1
kind: Job
metadata:
name: date
spec:
template:
spec:
containers:
- name: date
image: ubuntu:16.04
command: ["sh", "-c", "date > /date/date.txt"]
volumeMounts:
- mountPath: /date
name: date-volume
restartPolicy: Never
volumes:
- name: date-volume
hostPath:
path: /date
在这个 Job 中,我们定义了一个 Ubuntu 镜像的容器,用于将当前时间输出至宿主机的 /date/date.txt 文件中。将此 Job 创建好后,我们可以查看该 Job 对象:
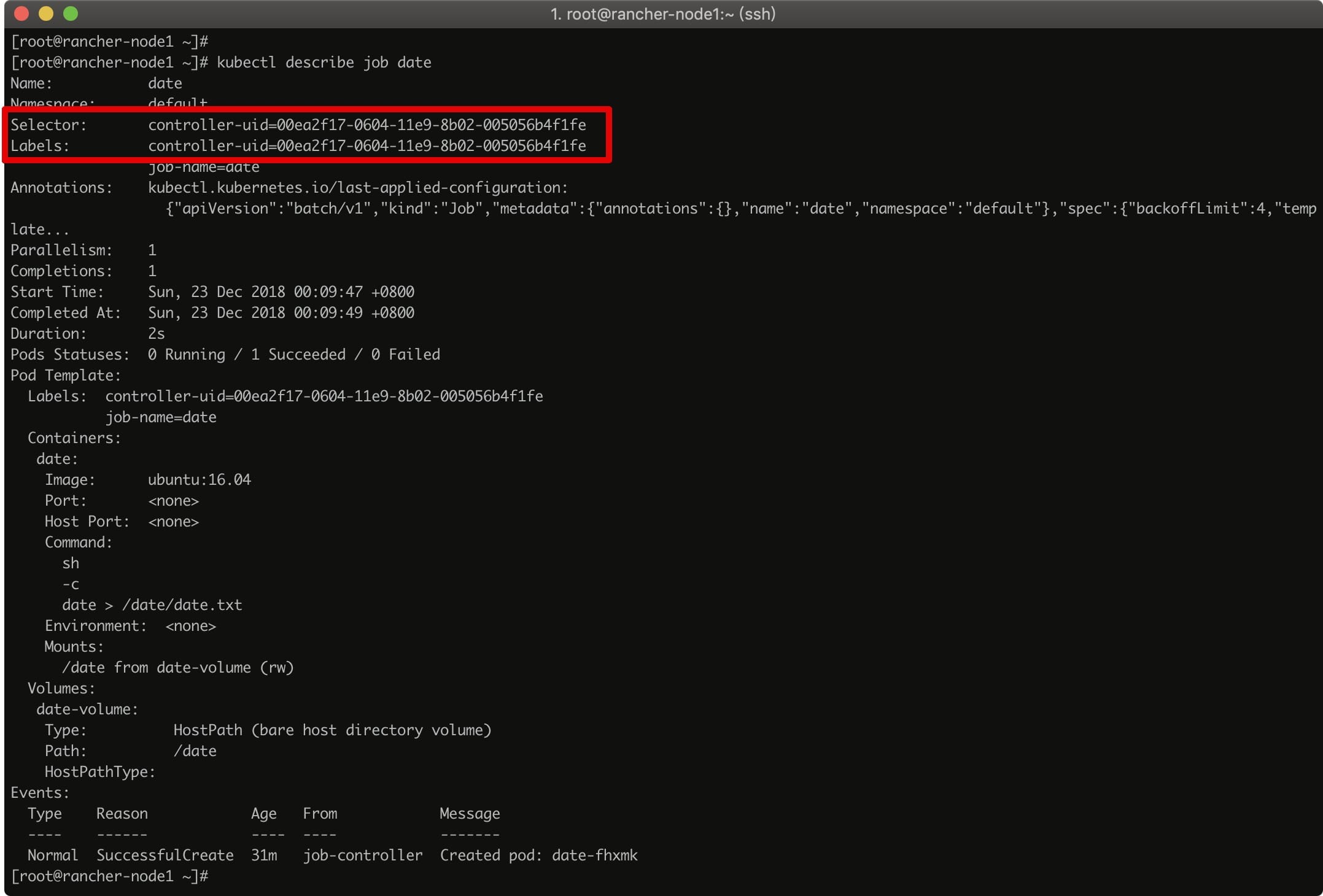
可以看到,Job 在创建后被加上了 controller-uid=***** 的 Label,和与之对应的 Label Selector,从而保证了 Job 与它所管理的 Pod 之间的匹配关系。查看 pod 可以看到相同的 Label:
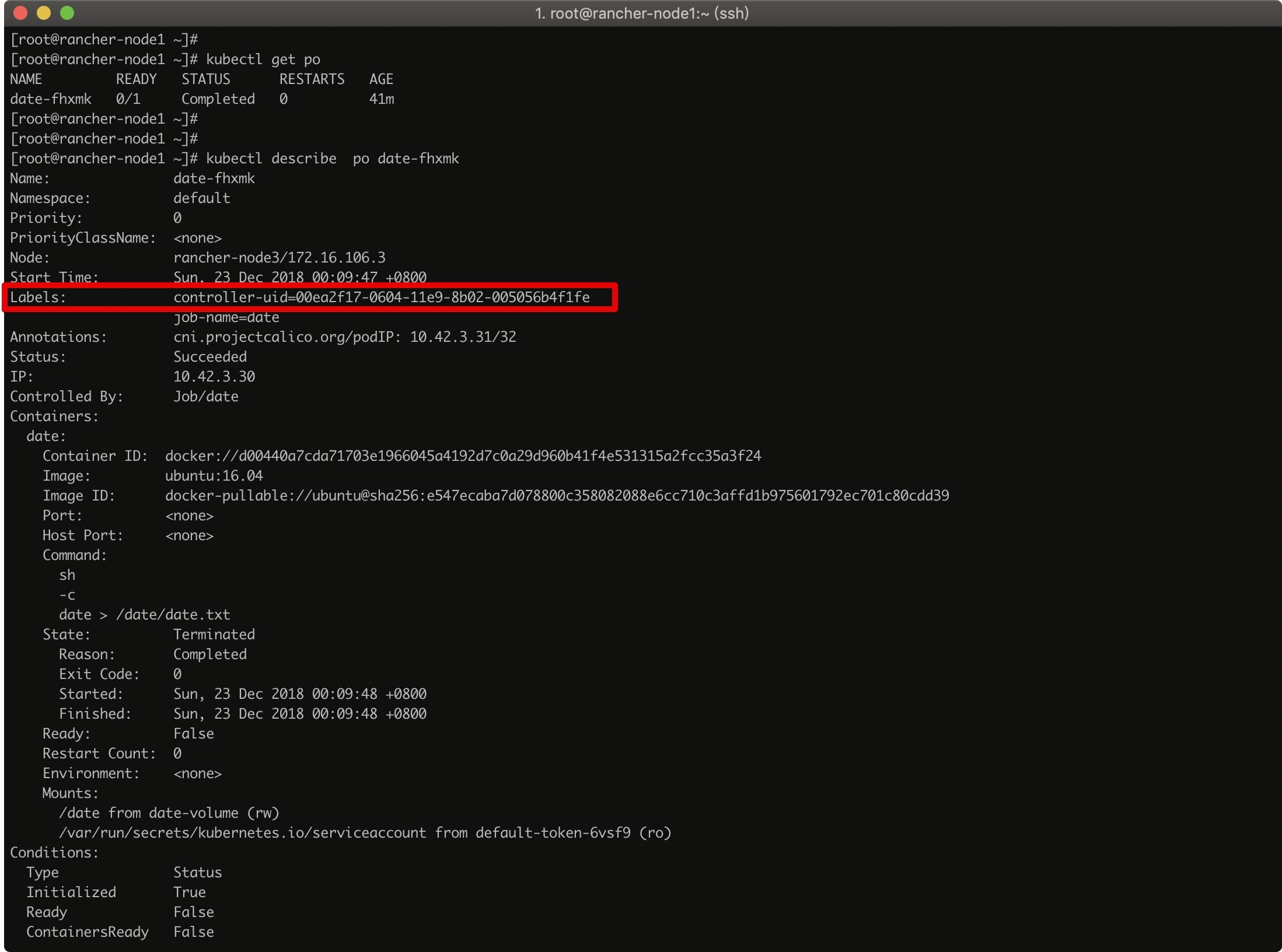
pod 在执行完毕后,状态会变成 Completed,我们可以去 pod 被调度的 node 上查看我们挂载进去的 date.txt 文件:
[root@rancher-node3 ~]# cat /date/date.txt
Sat Dec 22 16:09:48 UTC 2018
pod 重启策略
在 Job 中,pod 的重启策略 restartPolicy 不允许被设置成 Always,只允许被设置为 Never 或 OnFailure。这是因为 Job 的 pod 执行完毕后直接退出,如果 restartPolicy=Always,pod 将不断执行计算作业,这可不是我们期望的。
Job 可以设置 pod 的最长运行时间 spec.activeDeadlineSeconds,一旦超过了这个时间,这个 Job 的所有 pod 都会被终止。
那么,如果 pod 的计算作业失败了,在不同的重启策略下会怎么办?
restartPolicy=Never
如果设置了 restartPolicy=Never,那么 Job Controller 会不断的尝试创建一个新的 pod 出来,默认尝试 6 次。当然这个值可以设置,即 Job 对象的 spec.backoffLimit 字段。
需要注意的是,重新创建 Pod 的间隔是呈指数增加的。
restartPolicy=OnFailure
如果设置了 restartPolicy=Never,那么 Job Controller 会不断的重启这个 pod。
Job 工作原理
通过观察 Job 的创建过程,不难看出 Job 维护了两个值 DESIRED 和 SUCCESSFUL,分别表示 spec.completions 和 成功退出的 pod 数。
而在 Job 对象中有两个参数意义重大,它们控制着 Job 的并行任务:
spec.parallelism :定义一个 Job 在任意时间最多可以启动同时运行的 Pod 数;
spec.completions :定义 Job 至少要完成的 Pod 数目,即 Job 的最小完成数。
弄清楚了这两个参数,我们再来看 Job 的工作原理。
首先,Job Controller 控制的直接就是 pod;
在整个 Job 的作业过程中,Job Controller 根据实际在 Running 的 pod 数、已成功退出的 pod 数、parallelism 值、completions 值,计算出当前需要创建或删除的 pod 数,去调用 APIServer 来执行具体操作。
就拿上面的例子说明,比如将 YAML 改成:
apiVersion: batch/v1
kind: Job
metadata:
name: date
spec:
parallelism: 2
completions: 3
template:
spec:
containers:
- name: date
image: ubuntu:16.04
command: ["sh", "-c", "date >> /date/date.txt"]
volumeMounts:
- mountPath: /date
name: date-volume
restartPolicy: Never
volumes:
- name: date-volume
hostPath:
path: /date
第一步:判断当前没有 pod 在 Running,且成功退出 pod 数为 0,当前最多允许 2 个 pod 并行。向 APIServer 发起创建 2 个 pod 的请求。此时 2 个 pod Running,当这 2 个 pod 完成任务并成功退出后,进入第二步;
第二步:当前 Running pod 数为 0,成功退出数为 2,当前最多允许 2 个 pod 并行,Job 最小完成数为 3。则向 APIServer 发起创建 1 个 pod 的请求。此时 1 个 pod Running,当这个 pod 完成任务并成功退出后,进入第三步;
第三步:当前成功退出 pod 数为 3,Job 最小完成数为 3。判断 Job 完成作业。
批处理调度
根据 Job 的这些特性,我们就可以用以实现批处理调度,也就是并行启动多个计算进程去处理一批工作项。根据并行处理的特性,往往将 Job 分为三种类型,即 Job 模板拓展、固定 completions 数的 Job、固定 parallelism 数的 Job。
Job 模板拓展
这种模式最简单粗暴,即将 Job 的 YAML 定义成外界可使用的模板,再由外部控制器使用这些模板来生成单一无并行任务的 Job。比如,我们将上面的例子改写成模板:
apiVersion: batch/v1
kind: Job
metadata:
name: date-$ITEM
spec:
template:
spec:
containers:
- name: date
image: ubuntu:16.04
command: ["sh", "-c", "echo item number $ITEM; date >> /date/date.txt; sleep 5s"]
volumeMounts:
- mountPath: /date
name: date-volume
restartPolicy: Never
volumes:
- name: date-volume
hostPath:
path: /date
而在使用的时候,只需将 $ITEM 替换掉即可:
cat job.yml | sed "s/\$ITEM/1/" > ./job-test.yaml
除了上面这张简单的基础模板使用,Kubernetes 官网还提供了一种以 jinja2 模板语言实现的多模板参数的模式:
{%- set params = [{ "name": "apple", "url": "http://www.orangepippin.com/apples", },
{ "name": "banana", "url": "https://en.wikipedia.org/wiki/Banana", },
{ "name": "raspberry", "url": "https://www.raspberrypi.org/" }]
%}
{%- for p in params %}
{%- set name = p["name"] %}
{%- set url = p["url"] %}
apiVersion: batch/v1
kind: Job
metadata:
name: jobexample-{{ name }}
labels:
jobgroup: jobexample
spec:
template:
metadata:
name: jobexample
labels:
jobgroup: jobexample
spec:
containers:
- name: c
image: busybox
command: ["sh", "-c", "echo Processing URL {{ url }} && sleep 5"]
restartPolicy: Never
---
{%- endfor %}
在使用这种模式需要确保已经安装了 jinja2 的包:pip install --user jinja2 。
再执行一条 Python 命令即可替换:
alias render_template='python -c "from jinja2 import Template; import sys; print(Template(sys.stdin.read()).render());"'
cat job.yaml.jinja2 | render_template > jobs.yaml
或者直接进行 kubectl create:
alias render_template='python -c "from jinja2 import Template; import sys; print(Template(sys.stdin.read()).render());"'
cat job.yaml.jinja2 | render_template | kubectl create -f -
固定 completions 数的 Job
这种模式就真正实现了并行工作模式,且 Job 的完成数是固定的。
在这种模式下,需要一个存放 work item 的队列,比如 RabbitMQ,我们需要先将要处理的任务变成 work item 放入任务队列。每个 pod 创建时,去队列里获取一个 task,完成后将其从队列里删除,直到完成了定义的 completions 数。
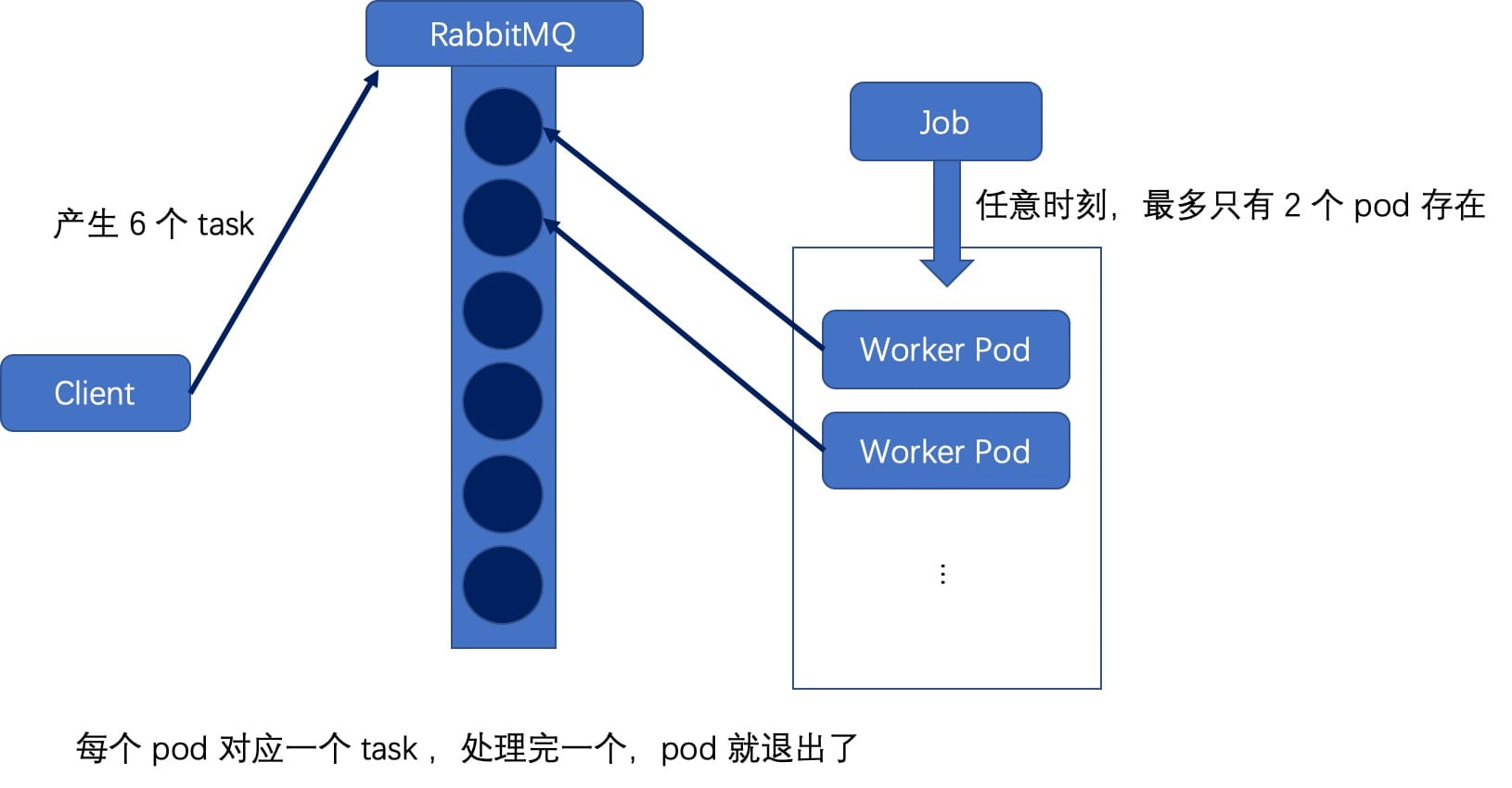
上图描述了一个 completions=6,parallelism=2 的 Job 的示意图。选择 RabbitMQ 来充当这里的工作队列;外部生产者产生 6 个 task ,放入工作队列中;在 pod 模板中定义 BROKER_URL,来作为消费者。一旦创建了这个 Job,就会以并发度为 2 的方式,去消费这些 task,直到任务全部完成。其 yaml 文件如下:
apiVersion: batch/v1
kind: Job
metadata:
name: job-wq-1
spec:
completions: 6
parallelism: 2
template:
metadata:
name: job-wq-1
spec:
containers:
- name: c
image: myrepo/job-wq-1
env:
- name: BROKER_URL
value: amqp://guest:guest@rabbitmq-service:5672
- name: QUEUE
value: job1
restartPolicy: OnFailure
固定 parallelism 数的 Job
最后一种模式是指定并行度(parallelism),但不设置固定的 completions 的值。
每个 pod 去队列里拿任务执行,完成后继续去队列里拿任务,直到队列里没有任务,pod 才退出。这种情况下,只要有一个 pod 成功退出,就意味着整个 Job 结束。这种模式对应的是任务总数不固定的场景。
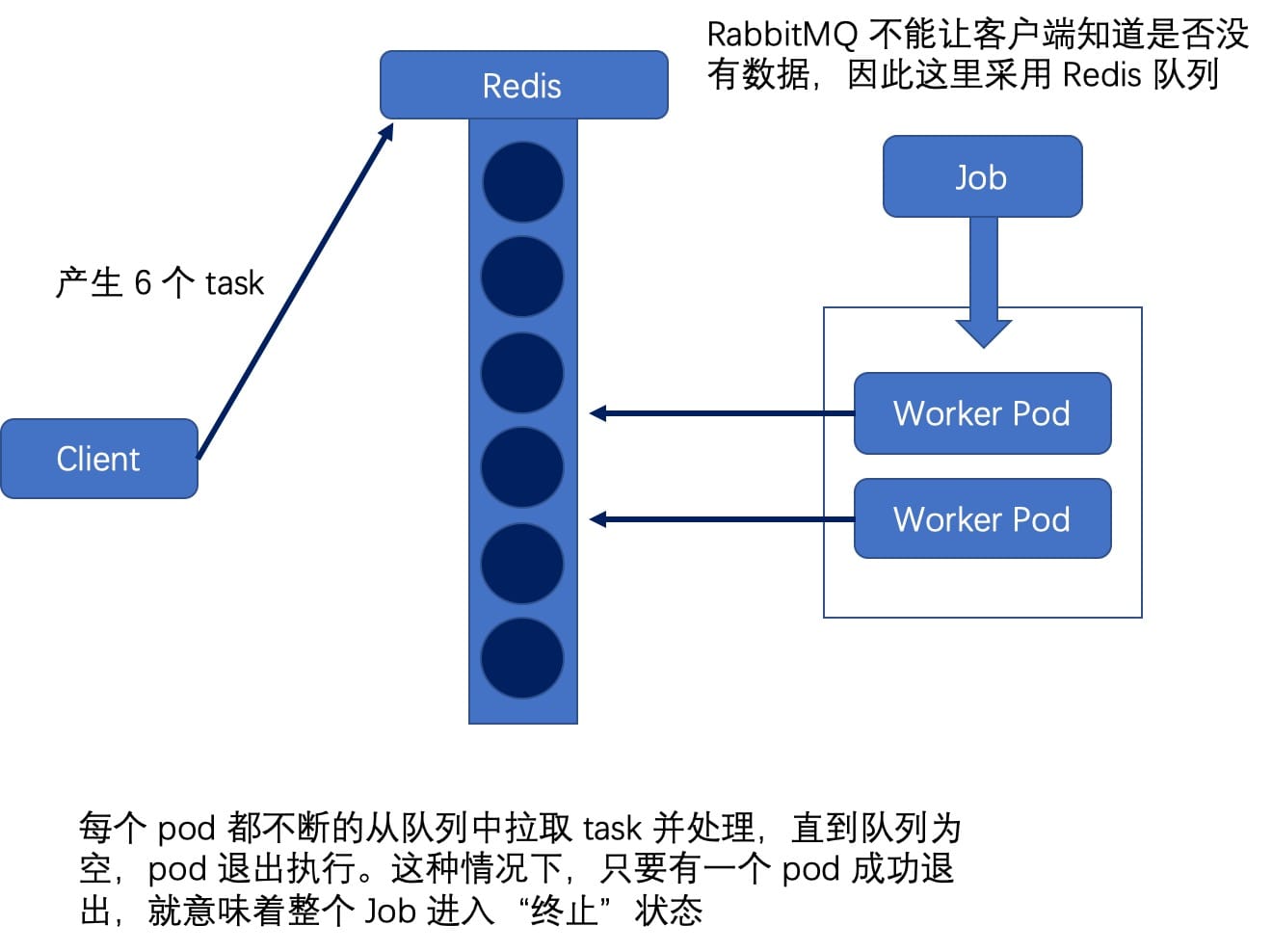
上图描述的是一个并行度为 2 的 Job。RabbitMQ 不能让客户端知道是否没有数据,因此这里采用 Redis 队列;每个 pod 去队列里消费一个又一个任务,直到队列为空后退出。其对应的 yaml 文件如下:
apiVersion: batch/v1
kind: Job
metadata:
name: job-wq-2
spec:
parallelism: 2
template:
metadata:
name: job-wq-2
spec:
containers:
- name: c
image: myrepo/job-wq-2
restartPolicy: OnFailure
CronJob
Kubernetes 在 v1.5 开始引入了 CronJob 对象,顾名思义,就是定时任务,类似 Linux Cron。先看个例子:
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: cron-date
spec:
schedule: "*/1 * * * *"
jobTemplate:
spec:
template:
spec:
containers:
- name: date
image: ubuntu:16.04
command: ["sh", "-c", "date >> /date/date.txt"]
volumeMounts:
- mountPath: /date
name: date-volume
nodeSelector:
kubernetes.io/hostname: rancher-node3
volumes:
- name: date-volume
hostPath:
path: /date
restartPolicy: OnFailure
CronJob 其实就是一个 Job 对象的控制器,需要定义一个 Job 的模板,即 jobTemplate 字段;另外,其定时表达式 schedule 基本上照搬了 Linux Cron 的表达式:
# ┌───────────── minute (0 - 59)
# │ ┌───────────── hour (0 - 23)
# │ │ ┌───────────── day of the month (1 - 31)
# │ │ │ ┌───────────── month (1 - 12)
# │ │ │ │ ┌───────────── day of the week (0 - 6) (Sunday to Saturday;
# │ │ │ │ │ 7 is also Sunday on some systems)
# │ │ │ │ │
# │ │ │ │ │
# * * * * *
创建出该 CronJob 对象后,CronJob 会记录下最近一次 Job 的执行时间:
[root@rancher-node1 jobs]# kubectl get cronjob cron-date
NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE
cron-date */1 * * * * False 0 22s 15m
[root@rancher-node1 jobs]# kubectl get job
NAME DESIRED SUCCESSFUL AGE
cron-date-1545584220 1 1 2m
cron-date-1545584280 1 1 1m
cron-date-1545584340 1 1 23s
[root@rancher-node1 jobs]# kubectl get po
NAME READY STATUS RESTARTS AGE
cron-date-1545584220-gzmzw 0/1 Completed 0 2m
cron-date-1545584280-bq9nx 0/1 Completed 0 1m
cron-date-1545584340-84tf2 0/1 Completed 0 27s
如果某些定时任务比较特殊,某个 Job 还没有执行完,下一个新的 Job 就产生了。这种情况可以通过设置 spec.concurrencyPolicy 字段来定义具体策略:
- concurrencyPolicy=Allow,这也是默认情况,这意味着这些 Job 可以同时存在;
- concurrencyPolicy=Forbid,这意味着不会创建新的 Pod,该创建周期被跳过;
- concurrencyPolicy=Replace,这意味着新产生的 Job 会替换旧的、没有执行完的 Job。
Kubernetes 所能容忍的 Job 创建失败数为 100,但是其失败时间窗口可以自定义。即通过字段 spec.startingDeadlineSeconds 可以用来设定这个时间窗口,单位为秒,也就是说在这个时间窗口内最大容忍数为 100,如果超过了 100,这个 Job 就不会再被执行。


